 Distributed Computing
Distributed Computing
STRUCO MEETING
Exchanges on Combinatorics, Distributed Computing and Graph Theory
-- Two perspectives meet --
-
Where
In Pont-à-Mousson, at the Abbaye des Prémontrés.
-
Who
The people coming.
-
When
In November, from 12th to 15th.
-
What
Informal atmosphere with free time to work & cooperate. See the programme.
Abbaye des Prémontrés
The venue is a former abbey, now a cultural center open to visitors. This pretty architectural piece belongs to the order of Prémontrés, thereby providing a natural link with Prague through the Strahov Monastery, near Charles University. This quiet place shall provide a peaceful and hopefully inspirational environment. Abbey's website.
The abbey is located at Pont-à-Mousson, right between Nancy and Metz. A direct TGV links Charles de Gaulle Airport to the station "Lorraine TGV" (about 1h15); which is about 15mn. away from the abbey by taxi. From Paris, take a direct TGV to Nancy (1h30) and then a train to Pont-à-Mousson. The abbey is reachable from the station either by bus (line 2, 5mn or, possibly, line 4.) or by foot (15mn.).
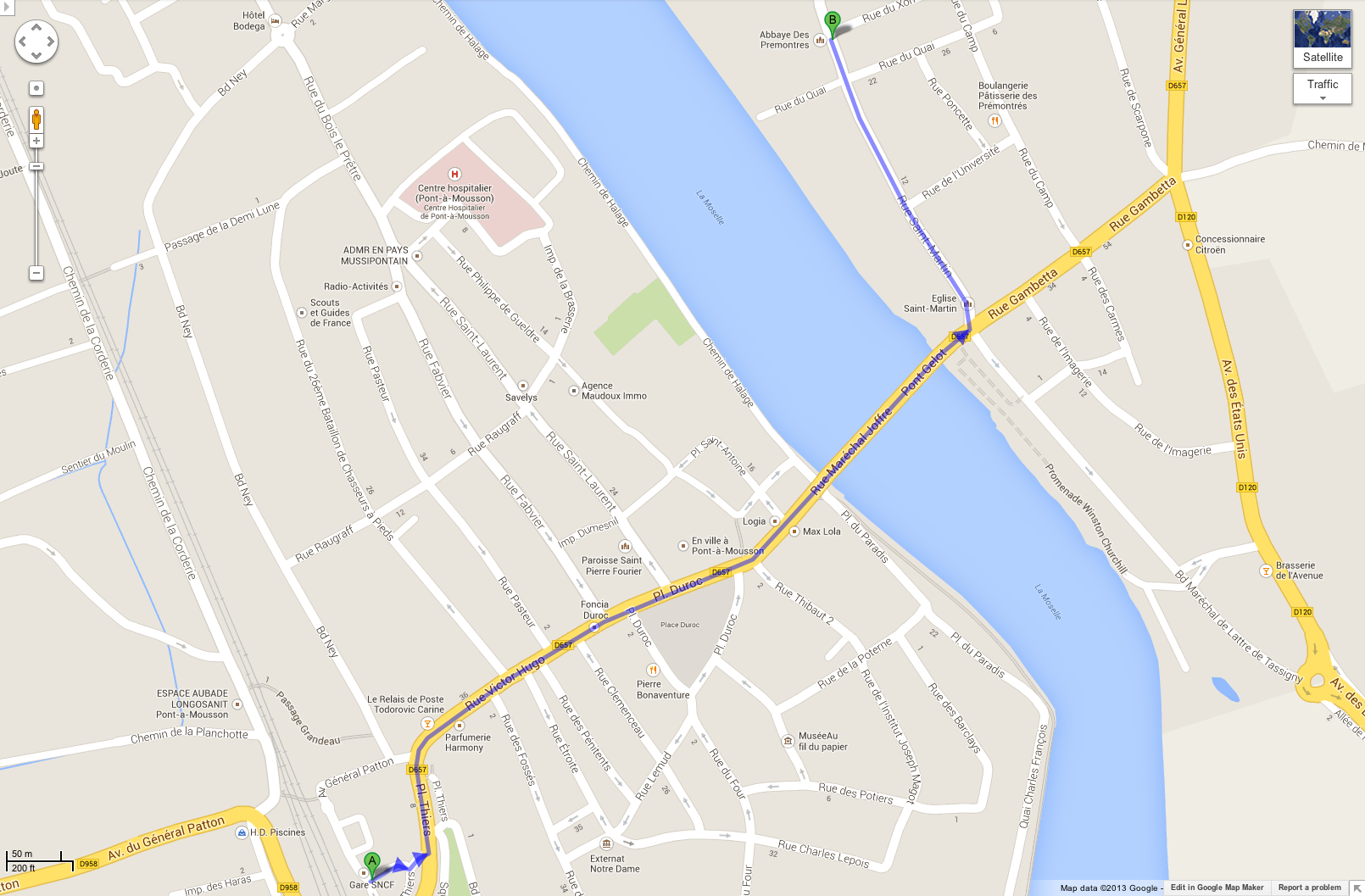 To Google maps.
To Google maps.


Tuesday
| 14h30 | Welcoming Coffee |
|---|---|
| 15h | F. Kuhn |
| 16h | P. Ossona de Mendez |
| 17h | break |
| 17h30 | A. Korman |
| 19h30 | dinner |
Friday
| 9h | Z. Dvořák |
|---|---|
| 10h | A. Goodall |
| 11h | break |
| 11h30 | time to work & cooperate |
| 12h30 | lunch |
Wednesday
| 9h | P. Fraigniaud |
|---|---|
| 10h | M. Habib |
| 11h | break |
| 11h30 | M. Loebl |
| 12h30 | lunch |
| 14 | F. Havet |
| 15h | open problem session: P. Charbit |
| 16h | break |
| 16h30 | time to work & cooperate |
| 19h | dinner |
Thursday
| 9h | J. Nešetřil |
|---|---|
| 10h | L. Viennot |
| 11h | break |
| 11h30 | time to work & cooperate |
| 12h30 | lunch |
| 14 | A. Korman |
| 15h | S. Rajsbaum |
| 16h | break |
| 16h30 | time to work & cooperate |
| 19h | dinner |
Zdeněk Dvořák:
Independent sets in triangle-free planar graphs (Slides)
(joint work with Matthias Mnich)By the 4-color theorem, every planar graph on n vertices has an independent set of size at least n/4. Finding a simple proof of this fact is a long-standing open problem. Furthermore, no polynomial-time algorithm to decide whether a planar graph has an independent set of size at least (n+1)/4 is known.
We study the analogous problem for triangle-free planar graphs. By Grötzsch's theorem, each such graph on n vertices has an independent set of size at least n/3, and this can be easily improved to a tight bound of (n+1)/3. We show that for every k, a triangle-free planar graph of sufficiently large tree-width has an independent set of size at least (n+k)/3, thus showing that the problem is fixed-parameter tractable when parameterized by k. Furthermore, we show that there exists a constant c < 3 such that every planar graph of girth at least five has an independent set of size at least n/c.
Pierre Fraigniaud:
Distributed decision for graph properties (Slides)
Deciding a graph property distributedly refers to the distributed task in which the nodes of a graph have to decide collectively, by exchanging messages with their neighbors, whether the graph satisfies some given predicate (e.g., being properly colored, being planar, etc.). In the common setting, if the graph satisfies the predicate then all nodes should output yes, while, if the graph does not satisfy the predicate, then at least one node should output no. This talk will survey some of the results in this field. It will discuss the local decidability of various predicates using deterministic, non-determinitic, randomized, or even quantum algorithms.
Patrice Ossona de Mendez:
Distributed low tree-depth decompositions (Slides)
We study the distributed low tree-depth decomposition problem on graphs bound to a bounded expansion class. Low tree-depth decomposition have been introduced in 2006 and have found quite a few applications, as a linear-time model checking algorithm for graphs in a bounded expansion class. Recall that bounded expansion classes cover classes of graphs of bounded degree, of planar graphs, of graphs of bounded genus, of graphs of bounded treewidth, of graphs that exclude a fixed minor, and many other graphs. Although there is a sequential algorithm to compute low tree-depth decompositions in linear time, there are currently no efficient distributed algorithms known for this problem. As traditional for symmetry breaking problem, we consider a synchronous model. As we are interested in a deterministic algorithm, we also use the common assumption that each vertex has a distinct identity number. Thus we are naturally led to consider Peleg's distributed message-passing ℒ𝒪𝒞𝒜ℒ model. In this model, we present a logarithmic time distributed algorithm for computing a low tree-depth decomposition of graphs in a fixed bounded expansion class.
Laurent Viennot:
Self-Organizing Flows in Social Networks (Slides)
(joint work with Nidhi Hegde and Laurent Massoulié, presented at SIROCCO 2013, PDF)Social networks offer users new means of accessing information, essentially relying on ``social filtering'', i.e. propagation and filtering of information by social contacts. The sheer amount of data flowing in these networks, combined with the limited budget of attention of each user, makes it difficult to ensure that social filtering brings relevant content to the interested users. Our motivation in this paper is to measure to what extent self-organization of the social network results in efficient social filtering. To this end we introduce flow games, a simple abstraction that models network formation under selfish user dynamics, featuring user-specific interests and budget of attention. In the context of homogeneous user interests, we show that selfish dynamics converge to a stable network structure (namely a pure Nash equilibrium) with close-to-optimal information dissemination. We show in contrast, for the more realistic case of heterogeneous interests, that convergence, if it occurs, may lead to information dissemination that can be arbitrarily inefficient, as captured by an unbounded ``price of anarchy''. Nevertheless the situation differs when users' interests exhibit a particular structure, captured by a metric space with low doubling dimension. In that case, natural autonomous dynamics converge to a stable configuration. Moreover, users obtain all the information of interest to them in the corresponding dissemination, provided their budget of attention is logarithmic in the size of their interest set.
Amos Korman:
An Optimal Ancestry Labeling Scheme (Slides)
(This talk is based on a joint work with Pierre Fraigniaud (CNRS))In this talk I discuss the ancestry-labeling scheme problem which aims at assigning the shortest possible labels (bit strings) to nodes of rooted trees, so that ancestry queries between any two nodes can be answered by inspecting their assigned labels only. This problem was introduced more than twenty years ago by Kannan et al. [STOC '88], and is among the most well-studied problems in the field of informative labeling schemes. We construct an ancestry-labeling scheme for n-node trees with label size log2 n + O(loglog n) bits, thus matching the log2 n + Ω(loglog n) bits lower bound given by Alstrup et al. [SODA '03]. Moreover, our scheme assigns the labels in linear time, and guarantees that any query can be answered in constant time.
Finally, our ancestry scheme finds applications to the construction of small universal partially ordered sets (posets). Specifically, for any fixed integer k, it enables the construction of a universal poset of size Õ(nk) for the family of n-element posets with tree-dimension at most k. Up to lower order terms, this bound is tight thanks to a lower bound of nk-o(1) due to Alon and Scheinerman [Order '88].
Amos Korman:
Integrating Theoretical Algorithmic Ideas in Empirical Biological Study (Slides)
(This talk is based on a joint work with Ofer Feinerman (Weizmann Institute))In recent years, several works have demonstrated how the study of biology can benefit from an algorithmic perspective. In this talk I discuss a new approach for such a methodology based on combining theoretical tradeoff techniques with biological experiments to obtain bounds on biological parameters. A proof of concept for this paradigm is provided by considering central search foraging strategies of desert ants, and obtaining theoretical tradeoffs between the search time and the memory complexity of individuals. Informally, we show that if the time-competitiveness of the search algorithm is below log k then the memory size of individuals (when starting the search) must be roughly loglog k, where k is the total number of individuals. Combining such bounds with successful experiments on living ants would provide a lower bound on the number of states ants have when commencing the search. Such a lower bound may serve as a quantitative evidence regarding the quorum sensing mechanism performed inside the nest.
Martin Loebl:
Optimization by Enumeration (Slides)
In this tutorial I first present the basic use of the Pfaffian method for the max-cut problem, and then review the graph polynomials approach to the graph isomorphism problem. If time allows, I will outline joint research with Jean-Sébastien Sereni.
Frédéric Havet:
Colouring weighted hexagonal graphs (Slides)
A weighted graph is a pair (G,C) where G is a graph and p: V(G) → N a weight function. A k-colouring of a weighted graph (G,p) is a function C that assigns to every vertex v a set C(v) of p(v) integers (colours) in {1,...,k} such that for any edge uv of G, the sets C(u) and C(v) are disjoint. Colouring weighted graphs is a natural problem for channel assignment in radio networks. The goal is to minimize the number of used channels, that is to find a k-colouring with the smallest possible k.
In practice, hexagonal graphs, which are induced subgraphs of the triangular lattice, crop up very often, because one usually aims to spread the transmitters out to form roughly a part of a triangular lattice, with hexagonal cells.
In this talk, we will present some bounds on weighted colouring of hexagonal graphs as well as (distributed) approximate algorithms.
Andrew Goodall:
Graph polynomials defined by graph homomorphisms (Slides)
(joint work with Delia Garijo and Jarik Nešetřil)The number of homomorphisms from a graph G to the complete graph Kk is the value of the chromatic polynomial of G at a positive integer k. Other important graph polynomials such as the Tutte polynomial and the independence polynomial, as well as the recently introduced polynomials of Averbouch, Godlin and Makowsky, and of Tittmann, Averbouch and Makowsky, are all likewise determined by counting homomorphisms from G to Hk for a sequence (Hk) of (possibly edge-weighted) graphs.
I will describe a general method of constructing sequences (Hk) of graphs that produce graph polynomials in this way. Starting with a constant sequence (H), which trivially produces a graph polynomial (taking constant value), these construction methods produce sequences such as (Kk) which do not so trivially produce a graph polynomial.
We have an infinite family of graph polynomials defined by colourings and yet not contained in the class of "generalized chromatic polynomials" of Makowsky and Zilber. The relationship with the broad class of SOL-definable graph polynomials of Courcelle, Godlin and Makowsky remains to be explored. Polynomials such as the chromatic polynomial which satisfy a recursive definition involving graph transformations definable in SOL (such as deletion and contraction of an edge) are themselves SOL-definable. Which of our polynomials satisfy such a recursive definition remains an open problem.
Sergio Rajsbaum:
Computability in Distributed Computing — The missing topic in Turing's Centenary Celebrations (Slides)
(joint work with Maurice Herlihy, Eli Gafni, Pierre Fraignaud and others)The equivalence between single-tape and multi-tape Turing machines is often interpreted as implying that sequential computing and distributed computing may differ in questions of efficiency, but not computability. It has been clear from early on that the addition of non-determinism or parallelism to Turing machines does not change the fundamental notion of Turing-computability.
However, a discussion of a more basic issue has not received much attention in the Turing Centenary celebrations. In the theory of Distributed Computing, we study computability aspects in the presence of failures and timing uncertainties. Turing computability is concerned with functions. A Turing machine starts with a single input, computes for a finite duration, and halts with a single output. In distributed computing, the analog of a function is called a task. Here, the input is split among the processes: initially each process knows its own part of the input, but not the others’. As each process computes, it communicates with the others, and eventually it halts with its own output value. Collectively, the individual output values form the task’s output. If the participants could reliably communicate with one another, then each one could assemble the individual inputs, and then compute sequentially the output to the task. In many realistic models of distributed computing, however, uncertainties caused by failures and unpredictable timing limit each participant to an incomplete picture of the global system state.
In this talk we provide an introduction to over almost 25 years of developments in this area. The story is a quest for a theory of distributed computability, and for a distributed akin to the Church-Turing Thesis.
Fabian Kuhn:
Decomposing Vertex Connectivity and Multiple Broadcasts in Vertex-Capacitated Networks (Slides)
Assume that we are given an n-node network G=(V,E) and that each node v ∈ V of the network has one bounded-size message that has to be broadcast to all the nodes of the network. For store-and-forward algorithms, it is not hard to see that for each message, the set of nodes that forward the message throughout an execution has to be a connected dominating set (CDS) of G. In order to achieve good throughput, it is therefore natural to ask into how many disjoint connected dominating sets, a graph G can be decomposed. This number is trivially upper bounded by the vertex connectivity k of the graph. We show that even for the fractional relaxation of the problem, there are graphs with vertex connectivity k, where the largest solution has size O(k/log n). For fractional CDS packings, we show that this bound is asymptotically tight. In addition, we show that every graph of vertex connectivity k can be decomposed into at least Ω(k/log5 n) disjoint connected dominating sets. Our results also have implications on the following natural question. Assume that in a graph G of vertex connectivity k, each node is independently sampled with some probability p. How large does p have to be such that the graph induced by the sampled nodes is with high probability connected? And if p is above this threshold, what is the vertex connectivity of the graph induced by the sampled nodes?
Michel Habib:
Graph clustering and community detection in networks (Slides)
In this lecture, I will present an overview of community detection algorithms in social networks and the relationships with graph clustering.
Community detection is nowadays a very hot subject since it is the first step for recommender algorithms used in Web sites (for example in Amazon). Unfortunately this problem is not very well formalized and it is therefore hard to compare existing methods. In fact they optimize various parameters, i.e. variation on a "modularity" defined by Newman and Girvan (2003).
Graph clustering which is a better formalized problem and it now used to deal with huge graph on distributed systems, for example with Map and Reduce environments.
I will finish by discussing open algorithmic problems and new search directions.