Pipeline
Le pipeline est un mécanisme permettant d'accroître la vitesse d'exécution des instructions dans un micro-processeur. L'idée générale est d'appliquer le principe du travail à la chaîne à l'exécution des instructions. Dans un micro-processeur sans pipeline, les instructions sont exécutées les unes après les autres. Une nouvelle instruction n'est commencée que lorsque l'instruction précédente est complètement terminée. Avec un pipeline, le micro-processeur commence une nouvelle instruction avant d'avoir fini la précédente. Plusieurs instructions se trouvent donc simultanément en cours d'exécution au cœur du micro-processeur. Le temps d'exécution d'une seule instruction n'est pas réduit. Par contre, le débit du micro-processeur, c'est-à-dire le nombre d'instructions exécutées par unité de temps, est augmenté. Il est multiplié par le nombre d'instructions qui sont exécutées simultanément.
Afin de mettre en œuvre un pipeline, la première tâche est de découper l'exécution des instructions en plusieurs étapes. Chaque étape est prise en charge par un étage du pipeline. Si le pipeline possède n étages, il y a n instructions en cours d'exécution simultanée, chacune dans une étape différente. Le facteur d'accélération est donc le nombre n d'étages. On verra que plusieurs problèmes réduisent ce facteur d'accélération. Sur les micro-processeurs actuels, le nombre d'étages du pipeline peut atteindre une douzaine ou même une vingtaine. La fréquence d'horloge est limitée par l'étape qui est la plus longue à réaliser. L'objectif des concepteurs de micro-processeurs est d'équilibrer au mieux les étapes afin d'optimiser la performance.
Pour le micro-processeur LC-3, on va découper l'exécution des instructions en les cinq étapes suivantes. On va donc construire un pipeline à cinq étages.
Ce schéma ne s'applique pas aux deux instructions LDI et STI qui nécessitent deux accès à la mémoire. Les processeurs utilisant un pipeline ne possèdent pas d'instruction avec ce mode d'adressage indirect. Dans la suite, on ignore ces deux instructions.
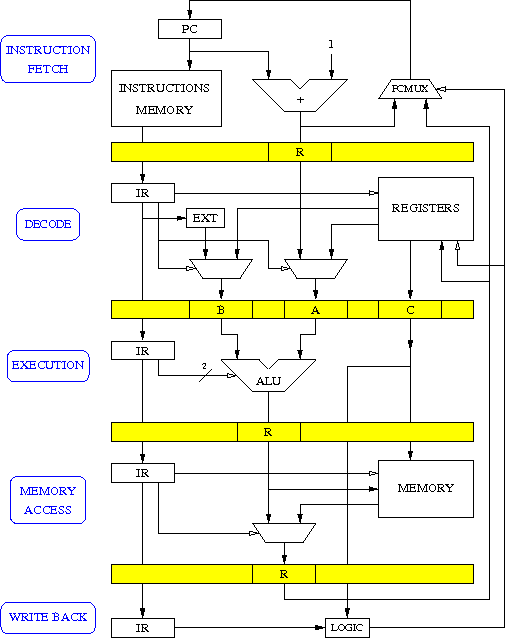
Le pipeline a réduit le nombre d'additionneurs puisque le même est utilisé pour les calculs arithmétiques et les calculs d'adresses. Par contre, certains registres ont dû être multipliés. Le registre d'instruction IR est présent à chaque étage du pipeline. En effet, l'opération à effectuer à chaque étage dépend de l'instruction en cours. Cette multiplication de certains éléments est le prix à payer pour l'exécution simultanée de plusieurs instructions.
Le tableau ci-dessous représente l'exécution d'un programme pendant quelques cycles d'horloge. Chacune des instructions commence son exécution un cycle après l'instruction précédente et passe par les cinq étapes d'exécution pendant cinq cycles consécutifs.
| Programme | Cycles d'horloge | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Inst. n° 1 | IF | ID | IE | MA | WB | |||||
| Inst. n° 2 | IF | ID | IE | MA | WB | |||||
| Inst. n° 3 | IF | ID | IE | MA | WB | |||||
| Inst. n° 4 | IF | ID | IE | MA | WB | |||||
| Inst. n° 5 | IF | ID | IE | MA | WB | |||||
| Inst. n° 6 | IF | ID | IE | MA | WB | |||||
Le pipeline est réalisé comme à la figure ci-dessous.
Pipeline
Le bon fonctionnement du pipeline peut être perturbé par plusieurs événements appelés aléas (pipeline hazard en anglais). Ces événements sont classés en trois catégories.
La solution générale pour résoudre un aléa est de bloquer l'instruction qui pose problème et toutes celles qui suivent dans le pipeline jusqu'à ce que le problème se résolve. On voit alors apparaître des bulles dans le pipeline. De manière pratique, la bulle correspond à l'exécution de l'instruction NOP qui ne fait rien.
| Programme | Cycles d'horloge | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| Inst. n° 1 | IF | ID | IE | MA | WB | |||||||
| Inst. n° 2 | IF | ID | IE | MA | WB | |||||||
| Inst. n° 3 | IF | ID | Bulle | IE | MA | WB | ||||||
| Inst. n° 4 | IF | Bulle | ID | IE | MA | WB | ||||||
| Inst. n° 5 | IF | ID | IE | MA | WB | |||||||
| Inst. n° 6 | IF | ID | IE | MA | WB | |||||||
Considérons par exemple le morceau de code suivant.
LDR R7,R6,0 ADD R6,R6,1 ADD R0,R0,1 ADD R1,R1,1
Le déroulement de l'exécution des quatre premières instructions dans le pipeline devrait être le suivant.
| Programme | Cycles d'horloge | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| LDR R7,R6,0 | IF | ID | IE | MA | WB | |||
| ADD R6,R6,1 | IF | ID | IE | MA | WB | |||
| ADD R0,R0,1 | IF | ID | IE | MA | WB | |||
| ADD R1,R1,1 | IF | ID | IE | MA | WB | |||
L'étape MA (accès mémoire) de l'instruction LDR R7,R6,0 a lieu en même temps que l'étape IF (chargement de l'instruction) de l'instruction ADD R1,R1,1. Ces deux étapes nécessitent simultanément l'accès à la mémoire. Il s'agit d'un aléa structurel. Comme cela est impossible, l'instruction ADD R1,R1,1 et celles qui suivent sont retardées d'un cycle.
| Programme | Cycles d'horloge | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
| LDR R7,R6,0 | IF | ID | IE | MA | WB | ||||||
| ADD R6,R6,1 | IF | ID | IE | MA | WB | ||||||
| ADD R0,R0,1 | IF | ID | IE | MA | WB | ||||||
| ADD R1,R1,1 | IF | ID | IE | MA | WB | ||||||
| Inst. n° 5 | IF | ID | IE | MA | WB | ||||||
| Inst. n° 6 | IF | ID | IE | MA | WB | ||||||
Le conflit d'accès à la mémoire se produit à chaque fois qu'une instruction de chargement ou de rangement est exécutée. Celle-ci rentre systématiquement en conflit avec le chargement d'une instruction qui a lieu à chaque cycle d'horloge. Ce problème est généralement résolu en séparant la mémoire où se trouvent les instructions de celle où se trouvent les données. Ceci est réalisé au niveau des caches de niveau 1. Le micro-processeur doit alors avoir deux bus distincts pour accéder simultanément aux deux caches.
Comme le micro-processeur LC-3 est très simple, les seuls aléas structurels possibles sont ceux dûs à des accès simultanés à la mémoire. Les registres sont utilisés aux étapes ID (décodage) et WB (rangement du résultat) mais les premiers accès sont en lecture et les seconds en écriture. Ceci ne provoque pas d'aléa.
Considérons le morceau de code suivant.
ADD R1,R1,1 ADD R0,R1,R2
Le déroulement de l'exécution de ces deux instructions dans le pipeline devrait être le suivant.
| Programme | Cycles d'horloge | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| ADD R1,R1,1 | IF | ID | IE | MA | WB | |
| ADD R2,R1,R0 | IF | ID | IE | MA | WB | |
Le problème est que le résultat de la première instruction est écrit dans le registre R1 après la lecture de ce même registre par la seconde instruction. La valeur utilisée par la seconde instruction est alors erronée.
Le résultat de la première instruction est disponible dès la fin de l'étape IE (exécution de l'instruction) de celle-ci. Il est seulement utilisé à l'étape IE de la seconde instruction. Il suffit alors de le fournir en entrée de l'additionneur à la place de la valeur lue dans R1 par la seconde instruction. Ceci est réalisé en ajoutant un chemin de données.
| Programme | Cycles d'horloge | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| ADD R1,R1,1 | IF | ID | IE | MA | WB | |
| ADD R2,R1,R0 | IF | ID | IE | MA | WB | |
Considérons un autre morceau de code assez semblable.
LDR R1,R6,0 ADD R0,R1,R2
Le déroulement de l'exécution de ces deux instructions dans le pipeline devrait être le suivant.
| Programme | Cycles d'horloge | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| LDR R1,R6,0 | IF | ID | IE | MA | WB | |
| ADD R2,R1,R0 | IF | ID | IE | MA | WB | |
Dans cet exemple encore, le résultat de la première instruction est écrit dans le registre R1 après la lecture de ce même registre par la seconde instruction. Par contre, le résultat n'est pas disponible avant l'étape MA (accès mémoire) de la première instruction. Comme cette étape a lieu après l'étape IE de la seconde instruction, il ne suffit pas d'ajouter un chemin de données pour faire disparaître l'aléa. Il faut en outre retarder la seconde instruction. Ceci introduit une bulle dans le pipeline.
| Programme | Cycles d'horloge | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| LDR R1,R6,0 | IF | ID | IE | MA | WB | ||||
| ADD R2,R1,R0 | IF | ID | IE | MA | WB | ||||
| Inst. n° 3 | IF | ID | IE | MA | WB | ||||
| Inst. n° 4 | IF | ID | IE | MA | WB | ||||
Considérons le morceau de programme suivant écrit dans un langage comme C.
x = x1 + x2; y = y1 + y2;
La compilation de ce morceau de code pourrait produire les instructions suivantes où x, x1, …, y2 désignent alors les emplacements mémoire réservés à ces variables.
LD R1,x1 LD R2,x2 ADD R0,R1,R2 ST R0,x LD R1,y1 LD R2,y2 ADD R0,R1,R2 ST R0,y
L'exécution de ces instructions provoque des aléas de données entre les instructions de chargement et les instructions d'addition. Ces aléas introduisent des bulles dans le pipeline. Ces bulles peuvent être évitées si le compilateur ordonne judicieusement les instructions comme dans le code ci-dessous. Plus de registres sont alors nécessaires.
LD R1,x1 LD R2,x2 LD R3,y1 ADD R0,R1,R2 LD R4,y2 ST R0,x ADD R0,R3,R4 ST R0,y
Lors de l'exécution d'une instruction de branchement conditionnel, on dit que le branchement est pris si la condition est vérifiée et que le programme se poursuit effectivement à la nouvelle adresse. Un branchement sans condition est toujours pris.
Lorsqu'un branchement est pris, l'adresse de celui-ci est calculée à l'étape IE (exécution de l'instruction) et rangée dans le registre PC à l'étape WB (rangement du résultat). Toutes les instructions qui suivent l'instruction de branchement ne doivent pas être exécutées. Au niveau du pipeline, on obtient le diagramme d'exécution suivant.
| Programme | Cycles d'horloge | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| Branchement | IF | ID | IE | MA | WB | |||||||
| Inst. suivante n° 1 | IF | ID | IE | |||||||||
| Inst. suivante n° 2 | IF | ID | ||||||||||
| Inst. suivante n° 3 | IF | |||||||||||
| Inst. cible n° 1 | IF | ID | IE | MA | WB | |||||||
| Inst. cible n° 2 | IF | ID | IE | MA | WB | |||||||
| Inst. cible n° 3 | IF | ID | IE | MA | WB | |||||||
On constate que l'exécution d'un branchement pris dégrade notablement la performance du pipeline puisque quatre cycles sont perdus. Comme les branchements constituent en général 20 à 30% des instructions exécutées par un programme, il est primordial d'améliorer leur exécution.
Dans le cas du micro-processeur LC-3, les instructions de branchement sont relativement simples. Une façon simple d'optimiser les branchements est de ne pas leur faire suivre toutes les étapes du pipeline afin que la nouvelle adresse soit écrite le plus tôt possible dans le registre PC.
Pour les branchements conditionnels, la condition ne dépend que des indicateurs n, z et p et du code de l'instruction. Cette condition peut donc être calculée à l'étape ID (décodage de l'instruction). De même, l'adresse du branchement est soit le contenu d'un registre soit la somme de PC et d'un offset. Dans les deux cas, cette valeur peut être rendue disponible à la fin de l'étape ID. Le prix à payer est l'ajout d'un nouvel additionneur dédié à ce calcul. La nouvelle adresse est alors écrite dans le registre PC à la fin de l'étape ID.
Le diagramme précédent devient alors le diagramme ci-dessous qui montre qu'il ne reste plus qu'un seul cycle d'horloge de perdu.
| Programme | Cycles d'horloge | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| Branchement | IF | ID | |||||||
| Inst. suivante n° 1 | IF | ||||||||
| Inst. cible n° 1 | IF | ID | IE | MA | WB | ||||
| Inst. cible n° 2 | IF | ID | IE | MA | WB | ||||
| Inst. cible n° 3 | IF | ID | IE | MA | WB | ||||