Un disque IFS est séparé en trois zones :
Une zone de description.
Une zone des nœuds.
Une zone de données.
La zone de description contient au moins 3 blocs (voir plus selon le nombre de nœuds du disque).
Le premier bloc est le « super-bloc » qui contient des données sur le disque
Le second bloc est le bloc d'adresse 1 qui correspond au symbole IFS_NULL. Par conséquent, pour éviter toute perte de données lors d'une erreur de manipulation de cette adresse, ce bloc ne contient pas de données significatives.
Les blocs suivants de la zone de description sont des « cartes » des nœuds de la zone des nœuds. Nous verrons par la suite leur utilisation.
Le super-bloc est divisé comme suit (toutes les valeurs contenues dans ce bloc sont écrites en little-endian):
Les quatre premiers octets contiennent le nombre hexadécimal 0x49465300(I F S ‘\0’) en notation little-endian, c'est à dire que les quatre premiers octets contiennent 00, 53, 46, 49.
Les quatre octets suivants contiennent le nombre de blocs utilisés pour la zone de description.
Les quatre octets suivants contiennent le nombre de blocs utilisés pour la zone des nœuds.
Les quatre octets suivants contiennent le nombre de bloc de la zone des données.
Les deux octets suivants contiennent le numéro du disque.
Les trente-deux octets suivants contiennent le nom du disque.
Les deux suivants contiennent l'adresse du dernier bloc du disque.
Les deux suivants contiennent l'adresse du premier bloc libre du disque (le système de gestion de la mémoire libre est expliqué plus en détail par la suite).
Les deux suivants contiennent le nombre de blocs de données libres.
Les deux suivants contiennent l'adresse du premier bloc de nœud du disque.
Les deux suivants contiennent le nombre de nœuds libres.
Les soixante-quatre suivants contiennent, au plus, trente-deux numéros de nœuds libres (en accès rapide).
Les deux suivants contiennent le nombre de nœuds en accès rapide.
Les deux derniers contiennent l'indice du nœud en accès rapide, suivant dans le tableau précédent.
Soit 128 octets en tout.
La zone des nœuds contient des informations sur les nœuds du système. Chaque bloc de cette zone contient les informations pour quatre nœuds. Chaque nœud est divisé comme suit :
Deux octets pour l'état (libre ou occupé)
Deux octets pour le type (répertoire, icône ou ordinaire)
Deux octets port le nombre de liens sur ce noeud
Deux octets pour l'adresse de l'icône de ce noeud
Vingt-deux octets pour onze adresses de blocs de données (dix directes et la dernière vers un bloc d'index de données)
La zone des données contient des blocs qui peuvent avoir différentes structures :
Les blocs de données qui n'ont pas de structures particulière.
Les blocs d'index de données qui ont un champs de deux octets pour stocker l'adresse du prochain bloc d'index et les cent vingt-six autres octets formants un tableau d'adresses de 63 blocs de données.
Les blocs de répertoire qui contiennent quatre entrées de répertoire Chaque entrée de répertoire est composée de deux champs. Le premier champs de trente octets permet de stocker le nom de l'entrée et le deuxième de deux octets permet de stocker le numéro du noeud correspondant à l'entrée du répertoire.
Les blocs libres n'ont pas de structures particulière en général sauf certains que nous qualifierons de blocs d'index-libre.
Les bloc d'index-libres qui sont décrits plus en détails par la suite, dans le paragraphe traitant de la gestion de la mémoire libre.
Pour gérer la mémoire nous avons adopté deux stratégies distinctes pour gérer les nœuds libres et les blocs de données libres : la « carte » de noeud et la liste chaînée de blocs d'index-libre.
Pour la gestion des nœuds libre, la stratégie employée est celle de la carte. Cette stratégie permet une implémentation simple de la gestion de l'espace libre tout en évitant de changer la structure de chaque bloc alloué ou libéré, cependant elle fait perdre un peu d'espace sur le disque.
Cette méthode consiste à référencer chaque noeud par un bit dans un bloc (le noeud n°0 correspond au bit n°0 du premier bloc-carte, le noeud n°1 correspond au bit n°1 du premier bloc-carte, etc...).
Pour signaler qu'un noeud est libre, le bit correspondant est positionné à 1 et pour signaler qu'un noeud est occuper, le bit correspondant est positionné à 0.
Ainsi pour trouver le premier noeud libre, il suffit de parcourir les bloc-cartes à la recherche du premier octet non nul, soit num_o son indice, puis de cherché dans cet octet l'indice du premier bit non nul, soit num_b cet indice. Si il n'y a qu'un bloc carte, on en déduit que le noeud numéro num_o × 8 + num_b est libre.
Pour éviter des recherches continuelles en cas de création ou de suppressions de nœuds, nous avons implémenté dans le super-bloc une liste de nœuds en accès rapide : à la création du disque, on la remplit avec les trente-deux premiers nœuds libres. Les demandes d'allocation ou de libération ce font par l'intermédiaire de cette liste. Si elle vient à se vider, on scanne à nouveau le bloc carte à la recherche de trente-deux nœuds libres suivants.
Cette méthode fonctionne très bien avec les nœuds qui sont relativement peu nombreux par rapports aux données. En effet, il faut tenir compte d'une perte de place relative : cette méthode utilise un bloc pour référencer 1024 nœuds, et devrait utiliser un bloc pour référencer 1024 blocs. Or bien que le système présenté est limité par l'utilisation d'un adressage sur deux octets à un disque d'environs 65 000 blocs, cela nous fera déjà perdre 64 blocs dans le pire des cas. Et dans le cas de système plus évolué, la perte d'espace serait encore plus grande. On peut donc envisager une autre technique pour la gestions des données libres.
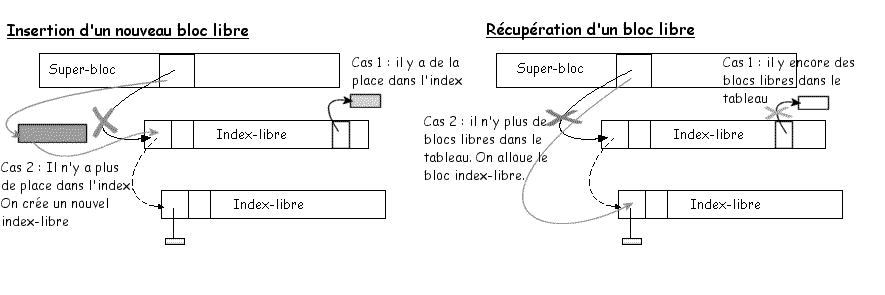
La méthode adoptée pour gérer les blocs de données libres consiste à chaîner des index-libres. Chaque bloc d'index-libre est composé de deux octets pointant sur le bloc d'index-libre suivant, de deux octets donnant le nombre de blocs libres dans l'index et d'un tableau de soixante-deux adresses de bloc directement libre.
Fonctionnement :
Une adresse dans le super-bloc pointe sur le premier bloc libre.(a la création du disque elle est initialisée avec le denier bloc dont le champs « suivant » pointe sur l'adresse IFS_NULL).
Insertion :
Pour insérer un nouveau bloc libre dans la structure, on l'insère dans la liste de l'index-libre pointé par le super-bloc. Si cette liste est complète, alors le nouveau bloc devient un index-libre pointant sur l'ancien premier index-libre et pointé par le super-bloc.
Récupération:
Pour récupérer un bloc libre, on le retire de la liste de l'index-libre pointé par le super-bloc. Si il n'y a plus de bloc disponible dans la liste, alors l'index-libre est lui-même alloué et le super-bloc pointe sur l'index-libre suivant.
Le cœur du système est constitué d'un serveur avec lequel dialogue les fonctions de l'API(Toute opération se passe au niveau du serveur). Le serveur permet de garder en mémoire des tables et une zone de cache.
Le choix d'un serveur pour implémenter le système demandé permet non seulement de garder en mémoires des données comme les fichiers ouverts ou les nœuds en mémoire mais aussi de fournir une meilleur simulation d'un système de fichiers. De plus, en modifiant un peu le serveur proposé qui est orienté mono utilisateur, on peut gérer avec cette méthode un système Multi-Utilisateur et introduire les systèmes distribués, où le système ne tourne pas sur la même machine que celle des utilisateurs.
Le serveur proposé est très simple :
On crée deux tubes IFS_IN et IFS_OUT qui servent aux communication.
On lance une boucle infinie
On ouvre le tube IFS_IN en lecture (opération bloquante attendant l'ouverture en écriture par un client).
On lit le message sur le tube dans une structure « requête »
On ferme le tube
On traître la requête et on rempli une structure « réponse » avec les résultats
On ouvre le tube IFS_OUT en écriture
On écrit la structure réponse dans ce tube
On ferme le tube
On recommence la boucle pour attendre la prochaîne requête
De leur côté, les clients ont accès a une fonction send(requête) et une fonction receive (réponse) qui permettent d'envoyer et de recevoir des message sur le même principe :
send:
On ouvre le tube IFS_IN en écriture
On écrit la structure requête dans le tube
On ferme le tube
receive:
On ouvre le tube IFS_OUT en lecture
On lit la structure réponse dans le tube
On ferme le tube
Pour déterminer le traitement à effectuer, la structure requête contient un code qui permet de déterminer la fonction de traitement à appeler.
Le système contient plusieurs tables qui permettent de garder des données en mémoires.
La table des disques permet un accès rapides au différents disques du système. Chaque entrée de la table des disque est soit vide soit contient une structure disque qui décrit l'un des disques du système, l'indice dans cette table est le numéro attribué au disque.
L'attribution d'un numéro a un disque se fait soit lors de sa création, si il a été créé sur ce système, ou lors du lancement du système, si il a été créé sur un autre système ifs. Elle se fait par une fonction de hachage qui détermine un pré-numéro, si la case en question est déjà occupée, on lui attribue la suivante et ainsi de suite. L'utilisation de la fonction de hachage permet un accès plus rapide quand on ne connaît que le nom du disque.
La structure de disque contient toutes les informations contenues dans le super-bloc du disque plus un champs permettant de savoir si la case de la table des disques est libre ou occupée et aussi le numéro du noeud du répertoire courant pour ce disque.
La table des nœuds en mémoire conserve en mémoire principale les noeud des répertoires en train d'être parcourus ou des fichiers ouverts par la commande open.
Chaque case a une structure particulière qui en plus du noeud contient le numéro de ce noeud et le numéro du disque contenant ce noeud. De plus un champs contient un compteur de fichier ouvert qui tient le compte des fichier ouvert faisant référence à ce noeud.
La commande close ferme un fichier ouvert et décrémente la valeur du compteur de fichier ouvert. Si cette valeur devient nulle le noeud est considéré comme supprimé de la table des nœuds en mémoire.
La table des fichiers ouverts conserve en mémoire des données sur les fichiers qui ont été ouverts par une commande ifs_open.
Il y a trois valeurs qui sont conservées :
le mode d'ouverture (M_ECR, M_LEC, M_EL, M_ZER, M_CRE)
l'offset, la position courante de lecture/écriture dans le fichier
un pointeur sur un noeud en mémoire dans la table du même nom
L'indice de la structure de fichier ouvert dans la table est le nombre qui sert de descripteur de fichier et qui est renvoyé par la fonction ifs_open.
Un fichier peut être ouvert plusieurs fois et dans ce cas le compteur du nombre de fichier ouvert sur ce noeud est incrémenté en conséquence.
Afin de limiter, les accès au disque, nous avons implémenté un système de caches qui permet d’effectuer une grande partie des entrées/sorties en mémoire principale plutôt que sur le disque.
La table des caches se présente sous la forme d'un tableau dont chaque case peut contenir un blocs et les informations sur la position du bloc (numéro du disque, adresse du bloc sur le disque).
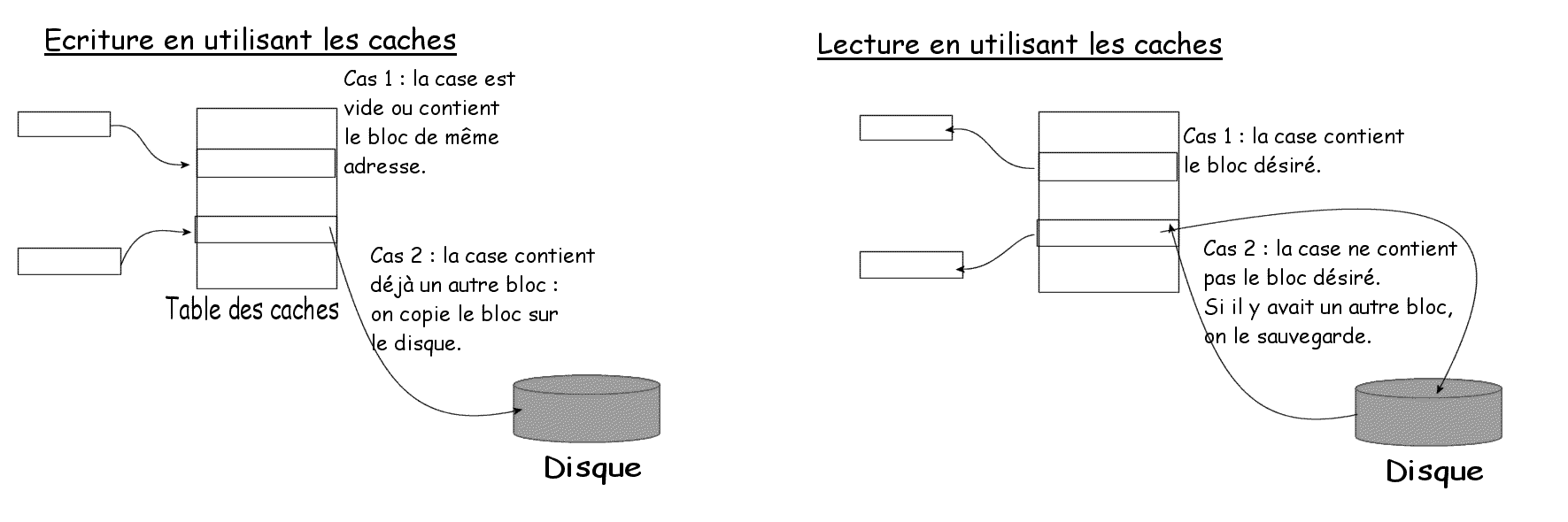
Fonctionnement en écriture :
Si je veux écrire un bloc en passant par la table des caches, il faut suivre les étapes suivantes:
Une fonction de hachage sur l'adresse du bloc calcul l'indice dans la table des caches
Si la case considérée est vide ou contient le bloc de même adresse, on écrase le contenu de la case.
Si la case contient déjà un autre bloc, on écrit ce bloc à sa place sur le disque avant d'écraser le contenu de la case.
Fonctionnement en lecture:
Si je veux lire un bloc en passant par la tables des caches, il faut suivre les étapes suivantes :
Une fonction de hachage calcule l'indice dans la table des caches
Si la case considérée est vide ou si elle contient un autre bloc, on copie le bloc du disque dans cette case en sauvegardant le bloc précédent dur le disque le cas échéant.
Si la case contient déjà le bloc désiré, il suffit de faire une copie de mémoire
L’avantage de cette fonctionnalité est qu’un moins grand nombre d'accès est nécessaire sur le disque, en particulier pour des blocs utilisés plusieurs fois de suite, comme les bloc d'index lors de l'écriture d'un fichier ou les nœuds.
L'inconvénient majeur de cette technique est que le disque et la mémoire ne sont pas forcément synchronisés, il faut donc de temps en temps synchroniser le disque (soit avec une horloge qui effectue cette opération toutes les n minutes, soit après n copie, etc...). En particulier, il est nécessaire de synchroniser le disque à l'arrêt du système.
Dans la conception actuelle du système, un plantage du serveur peut entraîner la perte de la structure du disque, pour empêcher cela, on peut utiliser un système de « copy on write » pour les données sensibles comme les nœuds où l'on force l'écriture sur le disque en même temps que l'écriture dans la table des caches.