Schematron est un autre formalisme permettant de spécifier la structure d'un document XML. C'est donc au départ une alternative aux schémas mais il est plutôt complémentaire des schémas. Ce formalisme n'est pas très adapté pour définir l'imbrication des éléments comme le font les DTD ou les schémas en donnant une grammaire. En revanche, il permet d'imposer des contraintes sur le document qu'il est difficile, voire impossible, d'exprimer avec les schémas. Il est fréquent d'utiliser les deux formalismes conjointement. Un schéma définit la structure globale du document et un schematron la complète en ajoutant des contraintes supplémentaires que doit satisfaire le document pour être valide. Il existe d'ailleurs des mécanismes permettant d'inclure un schematron au sein d'un schéma.
Schematron est basé sur XPath. Un schematron est constitué de règles écrites avec des expressions XPath qui expriment la présence ou l'absence de motifs dans le document. Ce mécanisme rend schematron très puissant puisqu'il est possible de mettre en relation des éléments et des attributs qui sont éloignés dans le document. Schematron reste cependant très simple car le vocabulaire est restreint. L'écriture d'un schematron requiert l'utilisation de seulement quelques éléments.
On donne ci-dessous un premier exemple de schematron très simple.
Il contient une seule règle qui s'applique aux éléments
list du document. Pour chacun de ces éléments,
la valeur de l'attribut length doit être égale au
nombre d'enfants.
<?xml version="1.0" encoding="utf-8"?> <sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron"><sch:title>Premier exemple de schematron</sch:title>
<sch:pattern> <sch:rule context="list">
<sch:assert test="@length = count(*)">
L'attribut length doit être égal au nombre d'enfants.
</sch:assert> </sch:rule> </sch:pattern> </sch:schema>
| Élément racine |
| Titre informatif du schematron. |
| Règle s'appliquant à tous les éléments |
| Contrainte proprement dite exprimée par une expression XPath. |
| Texte utilisé pour la fabrication du rapport. |
Si le schematron précédent est appliqué au document XML suivant, le
rapport va contenir le texte "L'attribut
... d'enfants." car la contrainte entre la valeur de
l'attribut length et le nombre d'enfants de l'élément
list n'est pas satisfaite par le deuxième élément
list du document.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<lists>
<list length="3">
<item>A</item><item>B</item><item>C</item>
</list>
<list length="4">
<item>1</item><item>2</item><item>3</item>
</list>
</lists>
Le résultat de la vérification du document ci-dessus avec le schematron donné précédemment est donné à la section suivante.
Le principe de fonctionnement de schematron est le suivant. Un document cible est validé avec un schematron en utilisant une application appropriée. Cette validation produit un rapport qui retrace les différentes étapes de la validation. Ce rapport contient des messages destinés à l'utilisateur. Ces messages peuvent provenir d'éventuelles erreurs mais ils peuvent aussi être positifs et confirmer que le document satisfait bien certaines contraintes. Ces différents messages sont produits par l'application de validation ou ils sont issus du schematron. Le schematron associe, en effet, des messages aux différentes contraintes qu'il contient. Ce rapport est souvent lui même un document XML.
La validation d'un document avec un schematron est souvent réalisée en deux phases. Dans une première phase, le schematron est transformé en une version compilée qui est indépendante du document. Dans une seconde phase, la version compilée est utilisée pour produire le rapport. La première phase est parfois, elle-même, scindée en plusieurs étapes afin de prendre en compte les règles et les blocs abstraits.
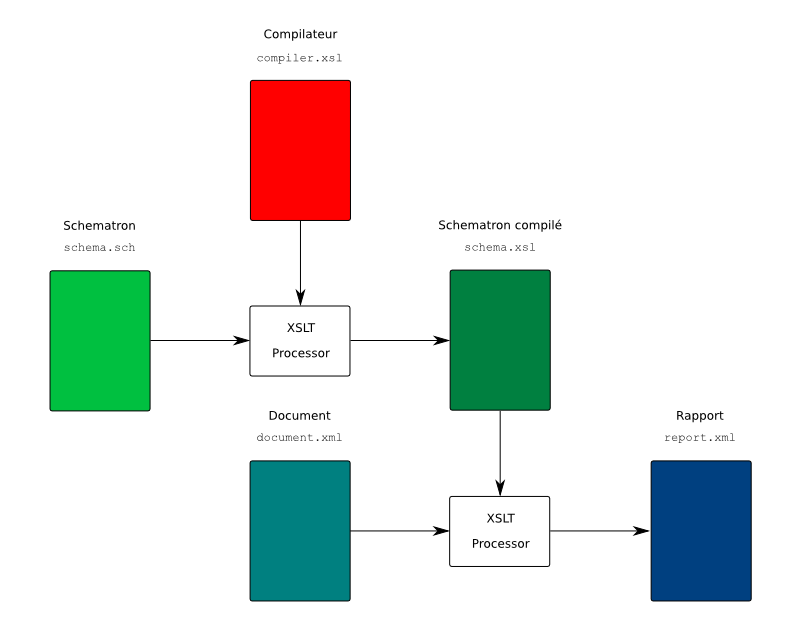
Il existe plusieurs implémentations de schematron souvent basées sur XSLT. Les deux phases sont réalisées par l'application de feuilles de style XSLT. Une première feuille de style XSLT transforme le schematron en une autre feuille de style XSLT qui constitue la version compilée du schematron. Cette dernière feuille de style est appliquée au document pour produire le rapport.
La composition exacte du rapport dépend de l'application qui
réalise la validation du document avec le schematron. Il contient des
fragments de texte issus du schematron mais aussi du texte produit par
l'application de validation. Ce rapport peut être un simple fichier
texte mais il est souvent un document XML, en particulier lorsque la
validation est réalisée via XSLT. Le format SVRL est un dialecte XML
conçu spécialement pour les rapports de validation avec des schematrons.
Il est en particulier utilisé par l'implémentation standard de schematron
disponible à l'adresse http://www.schematron.com/.
Le rapport SVRL obtenu par la validation du document XML avec le schematron donné ci-dessus est le suivant.
<?xml version="1.0" standalone="yes"?>
<svrl:schematron-output xmlns:svrl="http://purl.oclc.org/dsdl/svrl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:sch="http://purl.oclc.org/dsdl/schematron"
title="Comparaison attribut/nombre d'enfants"
schemaVersion="ISO19757-3">
<svrl:active-pattern/>
<svrl:fired-rule context="list"/>
<svrl:fired-rule context="list"/>
<svrl:failed-assert test="@length = count(*)" location="/lists/list[2]">
<svrl:text>L'attribut length doit être
égal au nombre d'enfants.</svrl:text>
</svrl:failed-assert>
</svrl:schematron-output>
L'ensemble d'un schematron est contenu dans un élément
sch:schema. L'espace
de noms des schematrons est identifié par l'URI
http://purl.oclc.org/dsdl/schematron. Il existe des
versions antérieures des schematrons qui utilisaient un autre espace de
noms. Le préfixe généralement associé à l'espace de noms est
sch comme dans cet ouvrage ou aussi
iso pour bien distinguer la version ISO actuelle des
schematrons des anciennes versions.
Un schematron est essentiellement constitué de règles regroupées en blocs. Il contient également du texte permettant de décrire les opérations effectuées. Il peut aussi déclarer des espaces de noms et des clés XSLT.
Lorsque les éléments des documents à valider appartiennent à un ou des espaces de noms, il est nécessaire de les déclarer dans le schematron et de leur associer des préfixes. Les préfixes sont nécessaires pour nommer correctement les éléments dans les expressions XPath des règles. Il faut en effet utiliser des noms qualifiés.
La déclaration d'un espace de noms se fait par l'élément
sch:ns dont les attributs prefix
et uri donnent respectivement le préfixe et l'URI qui
identifie l'espace de noms.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Comparaison attribut/nombre d'enfants</sch:title>
<!-- Déclaration de l'espace de noms cible associé au prefix tns -->
<sch:ns prefix="tns" uri="http://www.omega-one.org/~carton/"/>
<sch:pattern>
<!-- Le motif XPath utilise le nom qualifié de l'élément -->
<sch:rule context="tns:list">
<sch:assert test="@length = count(*)">
L'attribut length doit être égal au nombre d'éléments.
</sch:assert>
</sch:rule>
</sch:pattern>
</sch:schema>
Les règles d'un schematron sont regroupées en blocs. Chacun de
ces blocs est introduit par un élément
sch:pattern.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron">
...
<sch:pattern>
...
</sch:pattern>
<sch:pattern>
...
</sch:pattern>
...
</sch:schema>
Le contenu de chaque élément sch:pattern est
composé de règles. Chaque règle est donnée par un élément
sch:rule dont l'attribut context
détermine à quels nœuds la règle s'applique. Chaque règle contient
ensuite des tests introduits par les éléments
sch:assert et sch:report.
<sch:pattern>
<sch:rule context="...">
...
</sch:rule>
<sch:rule context="...">
...
</sch:rule>
...
</sch:pattern>
La validation d'un document avec un schematron consiste à traiter séquentiellement chacun des blocs de règles. Pour chaque bloc et pour chaque nœud du document cible est déterminée la règle à appliquer. Les différents tests de cette règle sont réalisés et des messages sont ajoutés au rapport en fonction des résultats de ces tests. Même si plusieurs règles peuvent s'appliquer à un nœud, une seule des règles du bloc est réellement appliquée. Il faut donc éviter la situation où plusieurs règles d'un même bloc s'appliquent potentiellement à un même nœud.
Le schematron ainsi que chacun de ses blocs peuvent être
commentés. Les éléments sch:schema et
sch:pattern peuvent avoir comme enfant un élément
sch:title pour donner un titre. Ils peuvent aussi
contenir des éléments sch:p prévus pour donner des
descriptions plus détaillées. Les contenus des éléments
sch:title et sch:p sont souvent
repris pour la construction du rapport.
Chaque règle est matérialisée par un élément
sch:rule qui contient un ou plusieurs tests.
L'élément sch:rule possède un attribut
context dont la valeur doit être un motif XPath. Ce motif détermine sur
quels nœuds s'applique la règle.
Les tests d'une règle sont introduits par les éléments
sch:assert et sch:report. Ces deux
éléments prennent la même forme. Ils possèdent un attribut
test dont la valeur est une expression XPath et ils
contiennent du texte qui est éventuellement utilisé pour construire le
rapport. Ces deux éléments se distinguent par leurs sémantiques qui sont
à l'opposé l'une de l'autre.
<sch:rule context="...">
<sch:assert test="...">
...
</sch:assert>
<sch:report test="...">
...
</sch:report>
...
</sch:rule>
Un test introduit par sch:assert est réalisé de
la façon suivante. L'expression XPath contenue dans l'attribut
test est évaluée en prenant le nœud sélectionné comme
contexte et le résultat de l'évaluation est converti en une valeur booléenne. Si le résultat est
false, le texte contenu dans l'élément
sch:assert est ajouté au rapport. Sinon rien n'est
ajouté au rapport.
Dans l'exemple ci-dessous, le message d'erreur est ajouté au
rapport si la condition n'est pas vérifiée, c'est-à-dire si l'élément
book n'a aucun des attributs id ou
key.
<sch:rule context="book">
<sch:assert test="@id|@key">
L'élément book doit avoir un attribut id ou key
</sch:assert>
</sch:rule>
Un test introduit par sch:report est, au
contraire, réalisé de la façon suivante. L'expression XPath contenue
dans l'attribut test est évaluée en prenant le nœud
sélectionné comme contexte et le résultat de l'évaluation est converti en
une valeur booléenne. Si le
résultat est true, le texte contenu dans l'élément
sch:report est ajouté au rapport. Sinon rien n'est
ajouté au rapport.
Dans l'exemple ci-dessous, le message d'erreur est ajouté au
rapport si la condition est vérifiée, c'est-à-dire si l'élément
book a simultanément les deux attributs
id et key.
<sch:rule context="book">
<sch:report test="count(@id|@key) > 1">
L'élément book doit avoir un seul des attributs id ou key
</sch:report>
</sch:rule>
Chaque règle peut bien sûr contenir plusieurs éléments
sch:assert et sch:report comme dans
l'exemple ci-dessous. L'ordre de ces différents éléments est sans
importance.
<sch:rule context="tns:pattern[@is-a]">
<sch:assert test="key('patid', @is-a)">
L'attribut is-a doit référencer un bloc abstrait.
</sch:assert>
<sch:report test="@abstract = 'true'">
Un bloc avec un attribut is-a ne peut pas être abstrait.
</sch:report>
<sch:report test="rule">
Un bloc avec un attribut is-a ne peut pas contenir de règle.
</sch:report>
</sch:rule>
Le texte contenu dans les éléments sch:assert et
sch:report peut aussi contenir des éléments
sch:name et sch:value-of qui
permettent d'ajouter du contenu dynamique. Lors de la construction du
rapport, ces éléments sont évalués et ils sont remplacés par le résultat
de leur évaluation. L'élément sch:name s'évalue en le
nom de l'élément sur lequel est appliqué la règle. Il est
particulièrement utile dans les règles abstraites et les
blocs abstraits où le
nom du contexte n'est pas fixé. L'élément
sch:value-of a un attribut select
contenant une expression XPath. L'évaluation de cette expression
remplace l'élément sch:value-of dans le rapport. Un
exemple d'utilisation de cet élément est donné à la section
suivante.
Une règle peut définir des variables locales introduites par des
éléments sch:let. Celles-ci mémorisent le résultat
d'un calcul intermédiaire pour des utilisations dans la règle. Chaque
élément sch:let a des attributs
name et value pour spécifier le
nom et la valeur de la variable. L'attribut value
doit contenir une expression XPath qui donne sa valeur à la variable.
Cette valeur ne peut plus ensuite être modifiée. Les éléments
sch:let doivent être les premiers enfants de
l'élément sch:rule. La variable ainsi déclarée est
disponible dans toute la règle.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Tests sur les heures</sch:title>
<sch:pattern>
<sch:rule context="time">
<sch:let name="hour" value="number(substring(.,1,2))"/>
<sch:let name="min" value="number(substring(.,4,2))"/>
<sch:let name="sec" value="number(substring(.,7,2))"/>
<!-- Test si l'heure est de la forme HH:MM:SS -->
<sch:assert test="string-length(.) = 8 and substring(.,3,1) = ':' and
substring(.,6,1) = ':'">
L'heure <sch:value-of select="."/> doit être au format HH:MM:SS.
</sch:assert>
<sch:assert test="$hour >= 0 and $hour <= 23">
Le nombre d'heures doit être compris entre 0 et 23.
</sch:assert>
<sch:assert test="$min >= 0 and $min <= 59">
Le nombre de minutes doit être compris entre 0 et 59.
</sch:assert>
<sch:assert test="$sec >= 0 and $sec <= 59">
Le nombre de secondes doit être compris entre 0 et 59.
</sch:assert>
</sch:rule>
</sch:pattern>
</sch:schema>
Le principe général des règles abstraites est d'avoir des règles
génériques susceptibles de s'appliquer à différents contextes. Le
contexte d'une règle, c'est-à-dire l'ensemble des nœuds sur lesquels elle
s'applique est normalement donné par son attribut
context. Il est possible de définir une règle sans
contexte qui définit seulement des contraintes. Elle ne peut pas être
utilisée directement mais d'autres règles l'utilisent en spécifiant le
contexte.
Une règle est déclarée abstraite avec un attribut
abstract ayant la valeur true. Elle
n'a pas d'attribut context. Elle possède, en
revanche, un attribut id qui permet de la désigner
pour l'utiliser. Une autre règle peut utiliser une règle abstraite en lui
fournissant un contexte. Elle fait appel à la règle abstraite grâce à
l'élément sch:extends dont l'attribut
rule donne l'identifiant de la règle abstraite.
Dans l'exemple suivant une règle abstraite de nom
has-title est définie. Elle vérifie que le nœud contexte
possède un enfant title et que celui-ci est le premier
enfant. Deux règles utilisent ensuite cette règle pour les éléments
book et chapter.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Utilisation de règles abstraites</sch:title>
<sch:pattern>
<!-- Règle abstraite qui teste si le premier enfant est title -->
<sch:rule abstract="true" id="has-title">
<sch:assert test="*[1][self::title]">
L'élément <sch:name/> doit avoir un enfant title qui
doit être le premier enfant.
</sch:assert>
</sch:rule>
<!-- Utilisation de la règle abstraite pour les éléments book -->
<sch:rule context="book">
<sch:extends rule="has-title"/>
<sch:assert test="chapter">
Le livre soit contenir au moins un chapitre.
</sch:assert>
</sch:rule>
<!-- Utilisation de la règle abstraite pour les éléments chapter -->
<sch:rule context="chapter">
<sch:extends rule="has-title"/>
<sch:assert test="para">
Le chapire soit contenir au moins un paragraphe.
</sch:assert>
</sch:rule>
</sch:pattern>
</sch:schema>
Ce schematron permet de vérifier que le document suivant n'est pas
correct. L'élément title n'est pas le premier
enfant du second chapter et le troisième
chapter n'a pas d'enfant
title.
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<book>
<title>Titre du livre</title>
<chapter>
<title>Premier chapitre</title>
<para>Ceci est le premier chapitre ...</para>
</chapter>
<chapter>
<para>Paragraphe avant le titre ...</para>
<title>Titre mal placé</title>
<para>Second paragraphe du second chapitre après le titre ...</para>
</chapter>
<chapter>
<para>Chapitre sans titre</para>
</chapter>
</book>
Les blocs abstraits généralisent le principe des règles abstraites. Ils déclarent des règles qui peuvent s'appliquer à différentes situations. Leur principe de fonctionnement est proche de celui des fonctions de n'importe quel langage de programmation. Un bloc abstrait contient des règles qui utilisent des paramètres. Ce bloc est alors utilisé par d'autres blocs qui instancient les paramètres en leur donnant des valeurs explicites.
Un bloc est déclaré abstrait avec un attribut
abstract ayant la valeur true. Il
a aussi un attribut id pour lui donner un identifiant.
Le bloc qui utilise un bloc abstrait doit avoir un attribut
is-a qui donne l'identifiant du bloc abstrait. Il ne
doit pas contenir de règles mais seulement des éléments
sch:param qui permettent d'instancier les paramètres.
L'élément sch:param a des attributs
name et value qui donnent
respectivement le nom du paramètre et la valeur qui lui est
affectée.
Le fonctionnement des blocs abstraits est semblable au passage de
paramètres des éléments xsl:apply-templates et xsl:call-template de
XSLT. En revanche, l'élément sch:param des
schematrons est l'analogue de l'élément xsl:with-param
de XSLT. L'élément xsl:param de XSLT n'a pas
d'équivalent dans les schematrons car les paramètres des blocs abstraits
ne sont pas déclarés.
Le schematron suivant définit un bloc abstrait de nom
uniq qui contient deux règles dépendant des paramètres
elem et desc. La première règle
vérifie que l'élément elem a au moins un descendant
desc. La seconde vérifie au contraire qu'il n'a pas
plus d'un descendant desc. Ces deux règles conjuguées
vérifient donc que l'élément elem a exactement un seul
descendant desc.
Le bloc abstrait uniq est ensuite utilisé par
les deux blocs uniq-id et
uniq-title. Le premier bloc donne les valeurs
book et @id|@key aux deux
paramètres elem et desc. Il
vérifie donc que chaque élément book possède
exactement un seul des deux attributs id et
key. Le second bloc donne les valeurs
book et title aux paramètres
elem et desc. Il vérifie donc que
chaque élément book possède exactement un seul enfant
title.
La vérification effectuée par le premier bloc n'est pas faisable avec les DTD et les schémas XML. Les déclarations d'attributs de ces deux langages se font sur chacun des attributs de façon indépendante. Il n'est pas possible d'exprimer une contrainte qui met en relation deux attributs ou deux éléments.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Utilisation de blocs abstraits</sch:title>
<!-- Déclaration du bloc abstrait -->
<sch:pattern abstract="true" id="uniq">
<!-- Les règles utilisent les paramètres elem et desc -->
<sch:rule context="$elem">
<sch:assert test="$desc">
L'élément <sch:name/> doit avoir un descendant $desc.
</sch:assert>
<sch:report test="count($desc) > 1">
L'élément <sch:name/> doit avoir un seul descendant $desc.
</sch:report>
</sch:rule>
</sch:pattern>
<!-- Utilisation du bloc abstrait -->
<sch:pattern is-a="uniq" id="uniq-id">
<sch:param name="elem" value="book"/>
<sch:param name="desc" value="@id|@key"/>
</sch:pattern>
<sch:pattern is-a="uniq" id="uniq-title">
<sch:param name="elem" value="book"/>
<sch:param name="desc" value="title"/>
</sch:pattern>
</sch:schema>
Le mécanisme des blocs abstraits est souvent implémenté comme les
#define du langage C. Chaque bloc qui utilise un bloc
abstrait est remplacé par une copie de celui-ci où les paramètres sont
substitués par leurs valeurs. Le schematron précédent est en fait
équivalent au schematron suivant. Le bloc abstrait
uniq a disparu mais ses règles apparaissent dupliquées
dans les deux blocs uniq-id et
uniq-title.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Substitution des blocs abstraits</sch:title>
<sch:pattern id="uniq-id">
<sch:rule context="book">
<sch:assert test="@id|@key">
L'élément <sch:name/> doit avoir un descendant @id|@key
</sch:assert>
<sch:report test="count(@id|@key) > 1">
L'élément <sch:name/> doit avoir un seul descendant @id|@key
</sch:report>
</sch:rule>
</sch:pattern>
<sch:pattern id="uniq-title">
<sch:rule context="book">
<sch:assert test="title">
L'élément <sch:name/> doit avoir un descendant title
</sch:assert>
<sch:report test="count(title) > 1">
L'élément <sch:name/> doit avoir un seul descendant title
</sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>
L'exemple ci-dessous illustre la puissance des schematrons. Ce
schematron exprime certaines contraintes que doivent satisfaire les
schematrons pour être valides. Ces contraintes portent sur les liens
entre les éléments pattern abstraits et ceux qui les
utilisent. Pour une meilleure efficacité, ce schématron utilise un index
créé par l'élément XSLT xsl:key.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<sch:title>Vérification des liens is-a des schematrons</sch:title>
<sch:p>Ce schematron vérifie que, dans un schematron, tout bloc référencé
par un autre bloc par l'attribut is-a est bien déclaré abstrait par
l'attribut abstract avec la valeur true.</sch:p>
<!-- Déclaration de l'espace de noms cible : celui des schematrons -->
<!-- Ne pas utiliser le préfixe sch car cela pose problème -->
<sch:ns prefix="tns" uri="http://purl.oclc.org/dsdl/schematron"/>
<!-- Clé pour retrouver les éléments pattern par leur id -->
<xsl:key name="patid" match="tns:pattern" use="@id"/>
<sch:pattern>
<sch:rule context="tns:pattern[@is-a]">
<sch:assert test="key('patid', @is-a)">
L'attribut is-a doit référencer un bloc abstrait.
</sch:assert>
<sch:report test="@abstract = 'true'">
Un bloc avec un attribut is-a ne peut pas être abstrait.
</sch:report>
<sch:report test="rule">
Un bloc avec un attribut is-a ne peut pas contenir de règle.
</sch:report>
</sch:rule>
</sch:pattern>
<sch:pattern>
<sch:rule context="tns:pattern[@abstract = 'true']">
<sch:assert test="@id">
Un bloc abstrait doit avoir un attribut id.
</sch:assert>
<sch:report test="@is-a">
Un bloc abstrait ne peut pas avoir un attribut is-a.
</sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>
Il est possible de regrouper les blocs en phases. Chaque phase est
identifiée par un nom. Lors de la validation d'un document par un
schematron, il est possible de spécifier la phase à effectuer. Seuls les
blocs appartenant à cette phase sont alors pris en compte. Ce mécanisme
permet de scinder un schematron en plusieurs parties et de procéder à une
validation incrémentale d'un document. Chaque phase déclare les blocs
qu'elle contient et un bloc peut appartenir à plusieurs phases. Lorsque
la validation par schematron est implémentée avec XSLT, la phase est
précisée en donnant un paramètre
global à la feuille de style XSLT. Il existe une phase par défaut
appelée #ALL qui comprend tous les blocs. Si aucune
phase n'est spécifiée, la validation utilise tous les blocs du
schematron.
Une phase est déclarée par un élément sch:phase
ayant un attribut id permettant de l'identifier.
Chaque bloc de cette phase est donné par un enfant
sch:active ayant un attribut
pattern qui précise l'identifiant du bloc.
Dans l'exemple minimal ci-dessous, il y a deux phases appelées
phase1 et phase2. Chacune de ces
deux phases contient un seul bloc.
<?xml version="1.0" encoding="utf-8"?>
<sch:schema queryBinding="xslt" schemaVersion="ISO19757-3"
xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Utilisation de phases</sch:title>
<!-- Phase 1 ne comprenant que le premier bloc -->
<sch:phase id="phase1">
<sch:active pattern="idkey"/>
</sch:phase>
<!-- Phase 2 ne comprenant que le second bloc -->
<sch:phase id="phase2">
<sch:active pattern="count"/>
</sch:phase>
<!-- Vérification des attributs id et key -->
<sch:pattern id="idkey">
<sch:rule context="book">
<sch:assert test="@id|@key">
L'élément book doit avoir un attribut id ou key
</sch:assert>
</sch:rule>
</sch:pattern>
<!-- Décompte du nombre de livres -->
<sch:pattern id="count">
<sch:rule context="bibliography">
<sch:report test="book">
Il y a <sch:value-of select="count(book)"/> livre(s).
</sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>