XPath est un langage permettant de sélectionner des parties d'un document XML. Il est utilisé dans de nombreux dialectes XML. Dans cet ouvrage, il est déjà apparu dans les contraintes de cohérence des schémas XML. Les schematrons du chapitre suivant sont essentiellement basés sur XPath. Le langage XSLT fait également un usage intensif de XPath pour désigner les parties à traiter.
Le langage XPath n'est pas un langage autonome. C'est un langage d'expressions utilisé au sein d'un autre langage hôte. Il ressemble, dans cet aspect, aux expressions rationnelles, appelées aussi expressions régulières qui est abrégé en regex telles qu'elles sont utilisées dans les langages de script tels que Perl ou Python.
La syntaxe de XPath n'est pas une syntaxe XML car les expressions XPath apparaissent en général comme valeurs d'attributs de documents XML. C'est en particulier le cas pour les schémas, les schematrons et XSLT.
XPath était au départ un langage permettant essentiellement de décrire des ensembles de nœuds dans un document XML. La version 1.0 de XPath comprenait quelques fonctions pour la manipulation de nombres et de chaînes de caractères. L'objectif était alors de pouvoir comparer les contenus de nœuds. La version 2.0 de XPath a considérablement enrichi le langage. Il est devenu un langage beaucoup plus complet capable, par exemple, de manipuler des listes de nœuds et de valeurs atomiques.
XPath est uniquement un langage d'expressions dont l'évaluation donne des valeurs sans effet de bord. Il n'est pas possible dans XPath de mémoriser un résultat. Il n'existe pas de variables propres à XPath mais une expression XPath peut référencer des variables du langage hôte. Les valeurs de ces variables sont alors utilisées pour évaluer l'expression. L'affectation de valeurs à ces variables se fait uniquement au niveau du langage hôte.
Le cœur de XPath est formé des expressions de chemins permettant
de décrire des ensembles de nœuds d'un document XML. Ces expressions
ressemblent aux chemins Unix pour nommer des fichiers
dans une arborescence.
Une expression XPath est généralement évaluée par rapport à un
document XML pour en sélectionner certaines parties. Le document XML est
vu comme un arbre formé de nœuds. Les principaux nœuds de cet arbre sont
les éléments, les attributs et le texte du document mais les commentaires
et les instructions de traitement apparaissent aussi comme des nœuds.
L'objet central de XPath est donc le nœud d'un document XML. XPath prend
aussi en compte les contenus des éléments et les valeurs des attributs
pour effectuer des sélections. Dans ce but, XPath manipule aussi des
valeurs atomiques des types
prédéfinis des schémas : xsd:string,
xsd:integer, xsd:decimal,
xsd:date, xsd:time ….
Il a été vu au chapitre sur la syntaxe que les éléments d'un document XML sont reliés par des liens de parenté. Un élément est le parent d'un autre élément s'il le contient. Ces relations de parenté constituent l'arbre des éléments. Cette structure d'arbre est étendue à tous les constituants d'un document pour former l'arbre du document qui inclut les éléments et leurs contenus, les attributs, les instructions de traitement et les commentaires. C'est sous cette forme d'arbre que le document XML est manipulé par XPath et XSLT.
L'arbre d'un document est formé de nœuds de différents types qui correspondent aux différents constituants possibles d'un document. Ces types de nœuds font partie du système de types de XPath. Ces types répartissent les nœuds en un nombre fini de catégories. Ce type ne doit pas être confondu avec le type associé à un nœud lorsque le document a été validé par un schéma. Ce dernier type est un type provenant du schéma.
- document node (root node)
Le nœud racine de l'arbre d'un document est un nœud particulier appelé document node ou root node dans la terminologie de XPath 1.0. Ce nœud ne doit pas être confondu avec l'élément racine qui est un enfant de ce document node.
- element node
Chaque élément du document est représenté par un nœud de ce type. Le contenu texte de l'élément n'est pas contenu dans ce nœud mais dans des nœuds textuels.
- attribute node
Chaque attribut est représenté par un nœud de ce type dont le parent est le nœud de l'élément ayant cet attribut. La valeur de l'attribut est contenue dans le nœud.
- comment node
Chaque commentaire du document est représenté par un nœud de ce type qui contient le texte du commentaire.
- processing instruction node
Chaque instruction de traitement est représentée par un nœud de ce type qui contient le texte de l'instruction.
- text node
Ces nœuds dits textuels encapsulent le contenu texte des éléments. Chaque fragment de texte non intérrompu par un élément, une instruction de traitement ou un commentaire est contenu dans un tel nœud. Le contenu textuel d'un élément est réparti dans plusieurs nœuds de ce type lorsque l'élément contient aussi d'autres éléments, des commentaires ou des instructions de traitement qui scindent le contenu textuel en plusieurs fragments.
- namespace node
Les nœuds de ce type représentaient en XPath 1.0 les espaces de noms déclarés dans un élément. Il sont obsolètes et ne doivent plus être utilisés. Ils sont remplacés par des fonctions XPath.
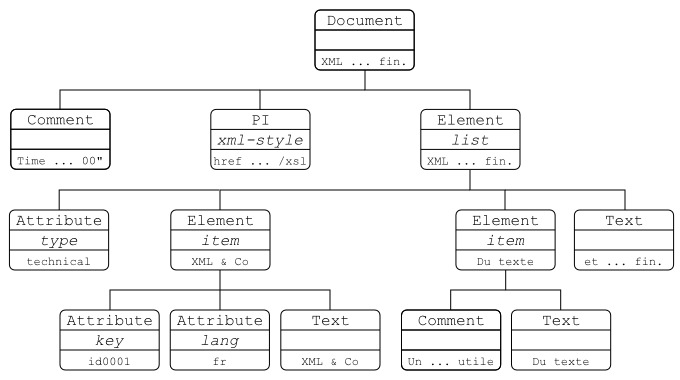
Afin d'illustrer ces types de nœuds, voici ci-dessous un document XML très simple ainsi que son arbre.
<?xml version="1.0" encoding="iso-8859-1"?> <!-- Time-stamp: "tree.xml 14 Feb 2008 09:29:00" --> <?xml-stylesheet href="tree.xsl" type="text/xsl"?> <list type="technical"> <item key="id001" lang="fr"> XML & Co </item> <item> <!-- Un commentaire inutile --> Du texte </item> et encore du texte à la fin. </list>
Dans la figure ci-dessous, chaque nœud de l'arbre est représenté par un rectangle contenant trois informations. La première information est le type du nœud, la deuxième est le nom éventuel du nœud et la troisième est la valeur textuelle du nœud.
Les nœuds de l'arbre d'un document sont caractérisés par un certain nombre de propriétés. Ces propriétés interviennent de façon essentielle dans la sélection des nœuds effectuée par Xpath. Suivant les types de nœuds, certaines propriétés n'ont pas de sens et elles n'ont alors pas de valeur. À titre d'exemple, le nœud d'un commentaire n'a pas de nom.
- nom
Pour le nœud d'un élément, d'un attribut ou d'une instruction de traitement, le nom est bien sûr le nom de l'élément, de l'attribut ou de l'instruction. Les nœuds des commentaires et les nœuds textuels n'ont pas de nom. Le nœud racine n'a également pas de nom.
- parent
Tout nœud à l'exception du nœud racine a un parent qui est soit le nœud racine soit le nœud de l'élément qui le contient. La relation parent/enfant n'est pas symétrique en XML. Bien que le parent d'un attribut soit l'élément qui le contienne, l'attribut n'est pas considéré comme un enfant de cet élément (cf. propriété suivante).
- enfants
Seuls le nœud racine et les nœuds des éléments peuvent avoir des enfants. Les enfants d'un nœud sont les nœuds des éléments, des instructions de traitement et des commentaires ainsi que les nœuds textuels qu'il contient. Les attributs ne font pas partie des enfants d'un élément. L'élément racine est un enfant du nœud racine qui peut aussi avoir des instructions de traitement et des commentaires comme enfants.
- valeur textuelle
Chaque nœud de l'arbre du document XML a une valeur qui est une chaîne de caractères Unicode. Pour un élément, cette valeur textuelle est le résultat de la concaténation des contenus de tous les nœuds textuels qui sont descendants du nœud. Ce texte comprend donc tout le texte contenu dans le nœud, y compris le texte contenu dans ses descendants. De manière imagée, cette chaîne est aussi obtenue en supprimant du contenu de l'élément les balises de ses descendants, les instructions de traitement et les commentaires. La valeur textuelle de l'élément
pdu fragment de document XML<p>Texte en <i>italique</i> et en <b>gras <i>italique</i></b></p>
est donc la chaîne
Texte en italique et en gras italique. La valeur textuelle est retournée par l'instruction XSLTxsl:value-of.Pour un attribut, la valeur textuelle est la valeur de l'attribut. Pour une instruction de traitement, c'est le texte qui suit le nom de l'instruction. Pour un commentaire, c'est le texte du commentaire sans les délimiteurs
<!--et-->. La valeur textuelle d'un nœud textuel est juste le texte qu'il contient.- type
Cette propriété n'existe que si le document a été un validé par un schéma. Il s'agit du type attribué à l'élément ou à l'attribut lors de la validation par le schéma. Ce type peut être un type prédéfini ou un type défini dans le schéma.
- valeur typée
Cette valeur n'existe que si le document a été un validé par un schéma. Il s'agit de la valeur obtenue en convertissant la valeur textuelle dans le type du nœud. Si le type d'un attribut est, par exemple,
xsd:doubleet sa valeur textuelle est la chaîne1.0e-3, sa valeur est le nombre flottant0.001. Cette conversion n'est possible que si le type du nœud est un type simple.
Chaque nœud a une valeur qui est utilisée à chaque fois qu'un
nœud apparaît là où une valeur atomique est requise. Beaucoup de
fonctions et d'opérateurs XPath prennent en paramètre des valeurs
atomiques. Lorsqu'un nœud est passé en paramètre à de tels fonctions
ou opérateurs, celui-ci est converti automatiquement en sa valeur. Ce
processus se déroule de la façon suivante. Si le nœud a une valeur
typée (c'est-à-dire lorsque le document est traité avec un schéma), la
valeur est la valeur typée et son type est celui de la valeur typée.
Sinon, la valeur est la valeur textuelle du nœud et son type est
xsd:untypedAtomic. Cette conversion d'un nœud en valeur
est appelée atomisation.
L'atomisation d'un nœud peut donner une liste de valeurs
atomiques éventuellement vide. C'est le cas lorsque le type du nœud
est un type de listes comme le type prédéfini
xsd:IDREFS ou les types construits avec l'opérateur
xsd:list.
Lorsqu'une liste contenant des nœuds doit être convertie en une liste de valeurs, chacun des nœuds est atomisé et sa valeur le remplace dans la liste. Lorsque la valeur du nœud comporte plusieurs valeurs atomiques, celles-ci s'insèrent dans la liste à la place du nœud.
Il existe des fonctions XPath permettant de récupérer les
propriétés d'un nœud. Les fonctions sont décrites avec leur type de
retour et le type de leurs paramètres. Les types utilisés sont ceux du
système de typage de
XPath. Lorsque le type du paramètre est node()?, la
fonction prend en paramètre un nœud ou rien. Dans ce dernier cas, le
paramètre est implicitement le nœud courant.
Fonctions sur les nœuds
xsd:string name(node()? node)retourne le nom complet du nœud
nodeou du nœud courant sinodeest absent.xsd:string local-name(node()? node)retourne le nom local du nœud
nodeou du nœud courant sinodeest absent. Le nom local est la partie du nom après le caractère':'qui la sépare du préfixe.xsd:QName node-name(node()? node)retourne le nom qualifié du nœud
nodeou du nœud courant sinodeest absent.xsd:string string(node()? node)retourne la valeur textuelle du nœud
nodeou du nœud courant sinodeest absent. Cette fonction ne doit pas être confondue avec la fonctionxsd:string()qui convertit une valeur en chaîne de caractères.xsd:anyAtomicType* data(node()* list)retourne les valeurs typées des nœuds de la liste
list.node() root(node()? node)retourne la racine de l'arbre qui contient le nœud
nodeou le nœud courant sinodeest absent.node()* id(xsd:string s)la chaîne
sdoit être une liste de noms XML séparés par des espaces. La fonction retourne la liste des nœuds dont la valeur de l'attribut de typeIDouxsd:IDest un des noms de la chaînes. La valeur passée en paramètre est souvent la valeur d'un attribut de typeIDREFouIDREFS. Pour qu'un attribut soit de typeID, il doit être déclaré de ce type dans une DTD. Il est aussi possible d'utiliser l'attributxml:idqui est de typexsd:ID.xsd:anyURI base-uri(node()? node)retourne l'URI de base du nœud
nodeou du nœud courant sinodeest absent.xsd:anyURI document-uri(node()? node)retourne l'URI de base du document contenant le nœud
nodeou le nœud courant sinodeest absent.xsd:anyURI resolve-uri(xsd:string? url, xsd:string? base)combine l'URI
uriavec l'URI de basebaseet retourne le résultat. Si l'URIbaseest omise et que le langage hôte est XSLT, c'est l'URI de base de la feuille de style qui est utilisée.
Les espaces de noms sont
manipulés en XPath 1.0 à travers l'axe namespace.
Cet axe est obsolète en XPath 2.0. Il est remplacé par des fonctions
permettant d'accéder aux espaces de noms.
xsd:string* namespace-uri(node()? node)retourne l'URI qui définit l'espace de noms dans lequel se trouve le nœud
nodeou le nœud courant sinodeest absent.xsd:string* in-scope-prefixes(node() node)retourne la liste des préfixes associés à un espace de noms dans le nœud
node. Si l'espace de noms par défaut est défini, la liste contient la chaîne vide. La liste contient toujours le préfixexmlassocié à l'espace de noms XML.xsd:string namespace-uri-for-prefix(xsd:string prefix, node() node)retourne l'URI qui définit l'espace de noms auquel est associé le préfixe
prefixdans le nœudnode.
- ⊳
for $i in in-scope-prefixes(.) return concat($i, '=', namespace-uri-for-prefix($i, .)) donne une chaîne formée d'un bloc de la forme
prefixe=uri
Tous les nœuds d'un document XML sont classés suivant un ordre appelé ordre du document. Pour les éléments, cet ordre est celui du parcours préfixe de l'arbre du document. Ceci correspond à l'ordre des balises ouvrantes dans le document. Un élément est toujours placé après ses ancêtres et ses frères gauches et avant ses enfants et ses frères droits. Les attributs et les déclarations d'espaces de noms sont placés juste après leur élément et avant tout autre élément. Les déclarations d'espaces de noms sont placées avant les attributs. L'ordre relatif des déclarations d'espaces de noms et l'ordre relatif des attributs sont arbitraires mais ils restent fixes tout au long du traitement du document par une application.
L'ordre du document peut être manipulé explicitement par les
opérateurs XPath '<<' et '>>'.
Il intervient aussi de façon implicite dans l'évaluation de certains
opérateurs, comme par exemple '/', qui ordonnent les nœuds de leur
résultat suivant cet ordre.
Les expressions XPath manipulent des valeurs qui sont soit des nœuds de l'arbre d'un document XML, soit des valeurs atomiques. Les principales valeurs atomiques sont les entiers, les nombres flottants et les chaînes de caractères. La donnée universelle de XPath est la liste de valeurs. Ces listes ne peuvent pas être imbriquées. Une liste contient uniquement des valeurs et ne peut pas contenir une autre liste. La longueur de la liste est le nombre de valeurs qu'elle contient. Les valeurs de la liste sont ordonnées et chaque valeur a une position allant de 1 (et non pas 0) pour la première valeur à la longueur de la liste pour la dernière valeur.
Les listes peuvent être construites explicitement avec l'opérateur
XPath ',' (virgule). L'opérateur XSLT
xsl:sequence
permet également de construire explicitement des séquences. Beaucoup
d'opérateurs et de fonctions XPath retournent des listes comme
valeurs.
Toute valeur est considérée par XPath comme une liste de longueur 1 contenant cette valeur. Inversement, toute liste de longueur 1 est assimilée à l'unique valeur qu'elle contient. Comme les listes ne peuvent pas être imbriquées, cette identification est assez naturelle et elle ne conduit à aucune confusion.
Les valeurs atomiques comprennent les chaînes de caractères, les entiers, les nombres flottants et tous les types prédéfinis des schémas XML. Les principaux types pour les valeurs atomiques sont les suivants. Pour chacun d'entre eux, un exemple de valeur est donné.
-
xsd:string Chaîne de caractères :
'string'ou"string"-
xsd:boolean Booléen :
true()etfalse()-
xsd:decimal Nombre décimal :
3.14-
xsd:floatetxsd:double Nombre flottant en simple et double précision
-
xsd:integer Entier :
42-
xsd:duration,xsd:yearMonthDurationetxsd:dayTimeDuration Durée :
P6Y4M2DT11H22M44Sde 6 ans, 4 mois, 2 jours, 11 heures 22 minutes et 44 secondes.-
xsd:date,xsd:timeetxsd:dateTime Date et heure :
2009-03-02T11:44:22-
xsd:anyURI URI :
http://www.omega-one.org/~carton/-
xsd:anyType,xsd:anySimpleTypeetxsd:anyAtomicType Types racine de la hiérarchie
-
xsd:untypedetxsd:untypedAtomic Nœud et valeur atomique non typés
XPath possède un système de typage assez rudimentaire qui permet de décrire les types des paramètres et le type de retour des fonctions. Ce système de typage est également utilisé par XSLT pour donner le type d'une variable lors de sa déclaration et pour les types de retour et des paramètres des fonctions d'extension. Les types des valeurs influent aussi sur les comportement de certains opérateurs et en particulier des comparaisons.
Ce système est organisé en une hiérarchie dont la racine est le
type item() (avec les parenthèses).
Tous les autres types dérivent de ce type qui est le plus général.
Toute valeur manipulée par XPath est donc de ce type.
Il y a ensuite des types pour les nœuds et des types pour les
valeurs atomiques. Pour les nœuds, il y a d'abord un type générique
node() ainsi que des types pour chacun
des types de nœuds. Ces types
sont document-node(), element(), attribute(), text(), processing-instruction() et comment() (avec les parenthèses). Les types pour
les valeurs atomiques sont les types prédéfinis des schémas
comme xsd:integer.
Toute valeur atomique extraite du document par atomisation est
typée. Lorsque le document est validé par un schéma avant traitement
par une feuille de style XSLT, les types des valeurs atomiques des
contenus d'éléments et des valeurs d'attributs sont donnés par le
schéma. Lorsque le document n'est pas validé par un schéma, toutes ces
valeurs atomiques provenant du document sont considérées du type
xsd:untypedAtomic.
Le système de type possède trois opérateurs '?', '*' et
'+', en notation postfixée, pour
construire de nouveaux types. Ils s'appliquent aux types pour les nœuds
et les valeurs atomiques décrits précédemment. L'opérateur
'?' désigne un nouveau type autorisant l'absence de
valeur. Ces types sont surtout utilisés pour décrire les paramètres
optionnels des fonctions. La fonction XPath name()
a, par exemple, un paramètre de type node()?. Ceci
signifie que son paramètre est soit un nœud soit rien. L'opérateur
'*' construit un nouveau type pour les listes. Le
type xsd:integer* est, par exemple, le type des
listes d'entiers éventuellement vides. L'opérateur
'+' construit un nouveau type pour les listes non
vides. Le type xsd:integer+ est, par exemple, le
type des listes non vides d'entiers.
L'évaluation d'une expression XPath se fait dans un contexte qui est fourni par le langage hôte. Le contexte se décompose en le contexte statique et le contexte dynamique. Cette distinction prend du sens lorsque les programmes du langage hôte sont susceptibles d'être compilés. Le contexte statique comprend tout ce qui peut être déterminé par une analyse statique du programme hôte. Tout ce qui dépend du document fait, au contraire, partie du contexte dynamique.
Les expressions XPath sont beaucoup utilisées dans les feuilles de style XSLT. Comme le langage XSLT est sans effet de bord, l'analyse statique des feuilles de styles XSLT est relativement facile et permet de déterminer beaucoup d'informations.
On rappelle que la portée d'une déclaration est l'élément qui
contient cette déclaration. Pour une déclaration d'espace de noms, c'est l'élément
contenant l'attribut xmlns. Pour une déclaration de
variable XSLT, la portée est
l'élément parent de l'élément xsl:variable. La
portée d'une définition d'une fonction d'extension est toute la
feuille de style car ces définitions sont enfants de l'élément racine.
On dit qu'un objet est en portée dans une
expression XPath si l'expression est incluse dans la portée de l'objet
en question. Le contexte statique comprend les objets suivants
- Espaces de noms
Tous les espaces de noms en portée, y compris éventuellement l'espace de noms par défaut. Le contexte comprend les associations entre les préfixes et les URI qui identifient les espaces de noms. Ceci permet de prendre en compte les noms qualifiés.
- Variables
Toutes les variables en portée et leur type éventuel. Les valeurs de ces variables font partie du contexte dynamique.
- Fonctions
Toutes les fonctions disponibles. Ceci comprend les fonctions standards de XPath, les fonctions de conversion de types et les fonctions d'extension définies au niveau du langage hôte.
- Collations
Toutes les collations en portée.
- URI de base
URI de base de l'élément.
La partie importante du contexte dynamique est appelée le focus et elle comprend trois valeurs appelées objet courant (context item dans la terminologie du W3C), position dans le contexte et taille du contexte. Le focus peut évoluer au cours de l'évaluation d'une expression.
L'objet courant est indispensable puisqu'il permet de résoudre
toutes les expressions relatives très souvent utilisées. L'objet
courant est très souvent un nœud du document mais il peut aussi être
une valeur atomique. Lorsque l'objet courant est un nœud, il est
appelé le nœud courant. C'est est un peu
l'équivalent du current working directory d'un
shell Unix. L'expression @id retourne, par exemple,
l'attribut id du nœud courant. L'évaluation de
certaines expressions, comme par exemple @id,
provoque une erreur si l'objet courant n'est pas un nœud. L'objet
courant est retourné par l'expression XPath '.' (point).
Il est fréquent qu'une expression XPath soit évaluée pour
différentes valeurs de l'objet courant prises dans une liste. L'objet
courant parcourt successivement les valeurs de cette liste qui peut
être déterminée avant l'évaluation ou au cours de l'évaluation de
l'expression XPath. Pour chaque valeur prise dans la liste par l'objet
courant, la position dans le contexte et la
taille du contexte sont respectivement la position
de la valeur dans liste et la taille de la liste. La taille du
contexte est bien sûr la même pour toutes les valeurs alors que la
position dans le contexte change pour chaque valeur. La position dans
le contexte et sa taille sont retournées par les deux fonctions XPath
position() et last().
- Variables locales
Certains opérateurs XPath comme
for,someeteveryintroduisent des variables locales qui font partie du contexte dynamique.- Valeurs des variables
Les valeurs de toutes les variables en portée.
- Définition des fonctions
Toutes les définitions des fonctions d'extension.
XSLT 1.0 possède une fonction number()
pour convertir une valeur quelconque en un entier.
Pour chaque type de base des schémas comme
xsd:boolean ou xsd:string, il
existe une fonction XPath de conversion ayant le même nom. Celle-ci
convertit une valeur quelconque en une valeur du type en question. La
fonction xsd:boolean() convertit, par exemple, une
valeur en une valeur
booléenne.
Certaines fonctions pouvant être utilisées dans les expressions XPath sont, en réalité, fournies par le langage hôte. Le langage XSLT fournit, en particulier, quelques fonctions très utiles. Il permet également de définir de nouvelles fonctions.
xsd:string format-number(number n, xsd:string format, xsd:ID id)retourne le nombre
nformaté avec le formatformatoù l'interprétation de ce format est donné par l'élémentxsl:decimal-formatidentifié parid.xsd:string generate-id(node()? node)retourne un identifiant pour le nœud
nodeou le nœud courant sinodeest absent. Au cours d'un même traitement, plusieurs appels àgenerate-idavec le même paramètre donnent le même identifiant. En revanche, des appels dans des traitements différents peuvent conduire à des résultats différents. Cette fonction est souvent utilisée pour produire une valeur destinée à un attribut de typeIDouxsd:IDcommexml:id.node() current()retourne le nœud courant auquel s'applique la règle définie par l'élément XSLT
xsl:template.node()* current-group()retourne la liste des nœuds du groupe courant lors de l'utilisation de l'élément XSLT
xsl:for-each-group.xsd:string current-grouping-key()retourne la clé courante lors de l'utilisation de l'élément XSLT
xsl:for-each-group.xsd:string regexp-group(xsd:integer n)retourne le fragment de texte entre une paire de parenthèses de l'expression rationnelle lors de l'utilisation de l'élément XSLT
xsl:matching-substring.
Le premier objectif de XPath est, comme son nom l'indique, d'écrire des chemins dans l'arbre d'un document XML. Ces chemins décrivent des ensembles de nœuds du document qu'il est ainsi possible de manipuler. Le cœur de XPath est constitué des opérateurs de chemins qui permettent l'écriture des chemins.
Le type fondamental de XPath est la liste mais les opérateurs de chemins retournent des listes où les nœuds sont dans l'ordre du document et où chaque nœud a au plus une seule occurrence. Ces listes représentent en fait des ensembles de nœuds. Ce comportement assure une compatibilité avec XPath 1.0 qui manipule des ensembles de nœuds plutôt que des listes.
Il existe deux syntaxes, une explicite et une autre abrégée pour les expressions de chemins. La première facilite la compréhension mais la seconde, beaucoup plus concise, est généralement utilisée dans la pratique. La syntaxe abrégée est décrite en mais la plupart des exemples sont donnés avec les deux syntaxes pour une meilleure familiarisation avec les deux syntaxes.
Les expressions de cheminement permettent de se déplacer dans
l'arbre d'un document en passant d'un nœud à d'autres nœuds. Une
expression de cheminement a la forme
axe::typetype qui sont reliés au nœud courant par la
relation axe. Parmi tous les nœuds,
l'axe effectue une première sélection basée sur la
position des nœuds dans l'arbre par rapport au nœud courant. Le type
raffine ensuite cette sélection en se basant sur le type et le nom des
nœuds. La sélection peut encore
être affinée par des filtres. Si l'objet courant
n'est pas un nœud, l'évaluation d'une telle expression provoque une
erreur. Les différents types correspondent aux différents nœuds pouvant
apparaître dans l'arbre d'un document.
L'axe par défaut est l'axe child qui
sélectionne les enfants du nœud courant.
node()tous les enfants du nœud courant, ce qui n'inclut pas les attributs
ancestor::*tous les ancêtres stricts du nœud courant
Chacun des axes donne une relation qui relie les nœuds sélectionnés au nœud courant. Les axes qu'il est possible d'utiliser dans les expressions XPath sont les suivants.
selfLe nœud lui-même (égalité)
childEnfant direct
parentParent
attributeAttribut du nœud
descendantDescendant strict
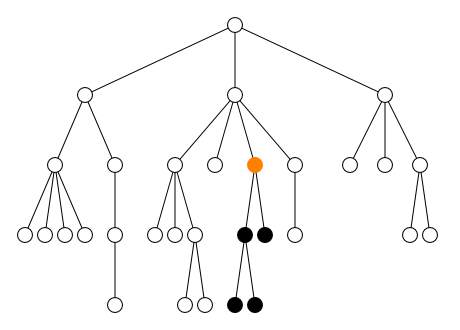
descendant-or-selfDescendant ou le nœud lui-même
ancestorAncêtre strict
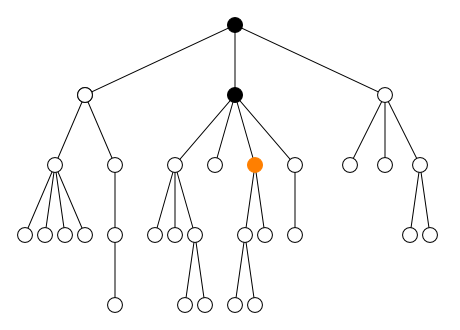
ancestor-or-selfAncêtre ou le nœud lui-même
preceding-siblingFrère gauche (enfant du même parent)
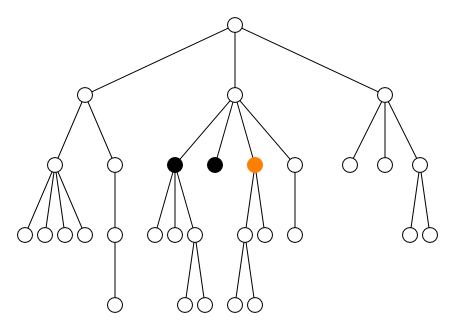
following-siblingFrère droit (enfant du même parent)
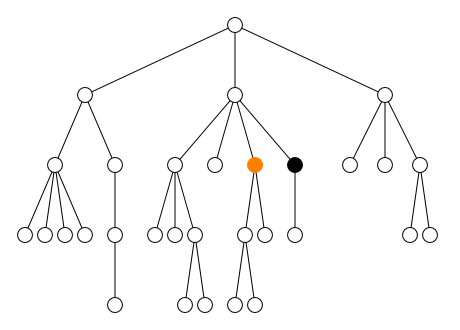
precedingÀ gauche
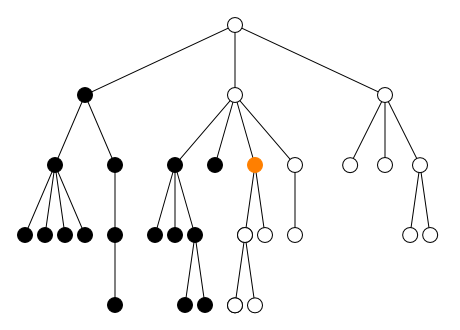
followingÀ droite
namespaceEspace de noms du nœud
L'axe namespace est un héritage de XPath 1.0
qui doit être considéré comme obsolète. Il est conseillé d'utiliser
les fonctions XPath pour
accéder aux espaces de noms d'un nœud.
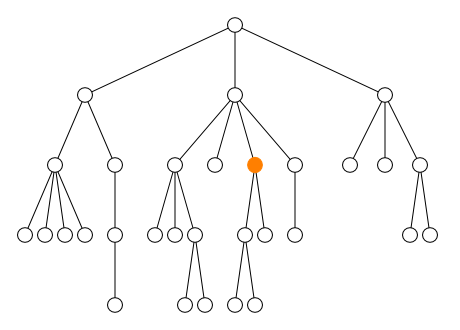
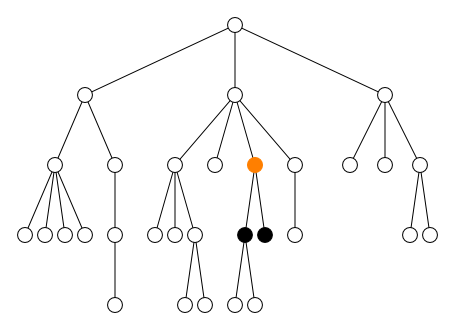
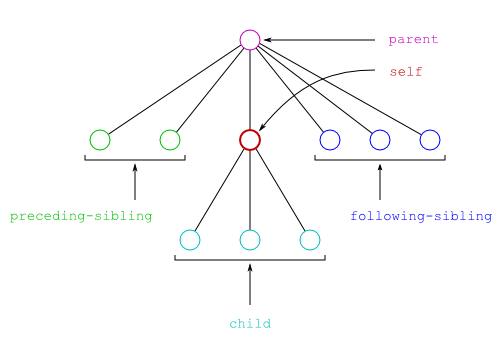
Les cinq axes self, parent,
child, preceding-sibling et
following-sibling sélectionnent le nœud lui-même et
les nœuds proches comme le montre la figure ci-dessous. Les nœuds
sélectionnés par ces cinq axes sont le nœud lui-même pour
self, le nœud juste au dessus pour
parent, les nœuds juste en dessous pour
child, les nœuds juste à gauche pour
preceding-sibling et les nœuds juste à droite pour
following-sibling.
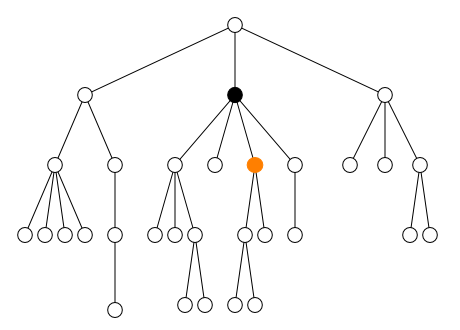
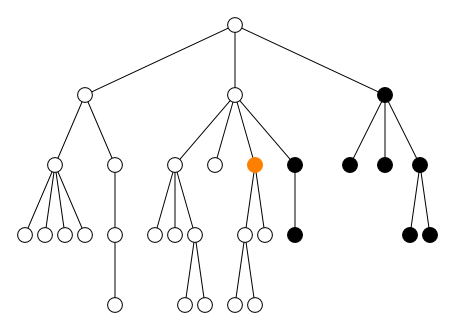
Au contraire, les quatre axes ancestor,
preceding, descendant et
following sélectionnent des nœuds qui peuvent être
très éloignés du nœud courant. Avec l'axe self, ces
quatre axes partitionnent l'ensemble de tous les nœuds du document en
cinq zones disjointes comme le montre la figure ci-dessous.
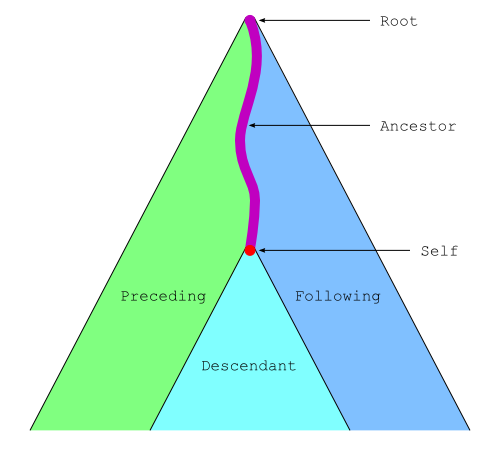
Une fois donné un axe, le type permet de restreindre l'ensemble des nœuds sélectionnés à un des nœuds d'une certaine forme. Les types possibles sont les suivants.
*tous les éléments ou tous les attributs suivant l'axe utilisé
ns:*tous les éléments ou tous les attributs (suivant l'axe) dans l'espace de noms associé au préfixe
ns*:localtous les éléments ou tous les attributs (suivant l'axe) de nom local
localnameles nœuds de nom
name(éléments ou attributs suivant l'axe utilisé)node()tous les nœuds
text()tous les nœuds textuels
comment()tous les commentaires
processing-instruction()ouprocessing-instruction(name)toutes les instructions de traitement ou les instructions de traitement de nom
name
Les types node(), text(),
comment() et
processing-instruction() se présentent comme des
pseudo fonctions sans paramètre. Les parenthèses sont indispensables
car les expressions text et
text() s'évaluent différemment. L'expression
text retourne les éléments de nom
text qui sont enfants du nœud courant alors que
l'expression text() retourne les nœuds textuels qui
sont enfants du nœud courant. Il faut, également, distinguer
l'expression string qui s'évalue en une liste de
nœuds de nom string des expressions
'string' et "string" qui
s'évaluent en une chaîne de caractères.
child::*ou*tous les éléments qui sont enfants du nœud courant
attribute::*ou@*tous les attributs du nœud courant
attribute::idou@idattribut
iddu nœud courantchild::node()ounode()tous les enfants du nœud courant
child::textoutexttous les éléments de nom
textqui sont enfants du nœud courant-
child::text()outext() tous les nœuds textuels qui sont enfants du nœud courant
descendant::comment()tous les commentaires qui sont descendants du nœud courant, c'est-à-dire contenus dans le nœud courant
following::processing-instruction()toutes les instructions de traitement qui suivent le nœud courant.
child::processing-instruction('xml-stylesheet')toutes les instructions de traitement de nom
xml-stylesheetqui sont enfants du nœud courant.
Les filtres permettent de
d'extraire d'une liste les objets qui satisfont une condition pour former
une nouvelle liste. Ils apparaissent beaucoup dans les expressions de
chemin pour restreindre le résultat d'une expression de cheminement.
Nous donnons ici quelques exemples d'utilisation de ces filtres.
Lorsque ces expressions XPath apparaissent comme valeur d'attributs, il
est nécessaire de remplacer les caractères spéciaux '<' et '>'
par les entités
prédéfinies.
-
child::*[position() < 4]ou*[position() < 4] les trois premiers éléments enfants du nœud courant
-
attribute::*[name() != 'id']ou@*[name() != 'id'] tous les attributs autres que
id. Cette expression peut aussi être écrite@* except @id.-
child::node()[position() = 4]ounode()[4] le quatrième enfant du nœud courant
-
child::section[position() = last()]ousection[position() = last()] dernier enfant
sectiondu nœud courant-
descendant::item[attribute::id]ou.//item[@id] tous les descendants du nœud courant qui sont un élément
itemayant un attributidancestor::*[@type='base']tous les ancêtres du nœud courant dont l'attribut
typeexiste et vautbase.-
chapter[count(child::section) > 1] élément
chapterayant au moins deux élémentssectioncomme enfants.
L'opérateur '/' permet de composer
des expressions de cheminement pour créer de véritables chemins dans un
arbre XML. C'est un des opérateurs clé de XPath. Sa sémantique est
proche du même opérateur '/' des shell Unix mais il
est plus général et pas toujours facile à appréhender
Une expression de la forme
expr1/expr2expr1 est d'abord évaluée pour donner une
liste d'objets. Pour chacun des objets de cette liste, l'expression
expr2 est évaluée en modifiant dynamiquement
le focus de la façon
suivante. L'objet courant est fixé à l'objet choisi dans la liste, la
position dans le contexte est fixée la position de cet objet dans la
liste et la taille du contexte est également fixée à la taille de la
liste. Les listes retournées par chacune des évaluations de
expr2, sont fusionnées pour donner une liste
de nœuds dans l'ordre du document et avec au plus une occurrence de
chaque nœud dans la liste. Cette liste est alors le résultat de
l'évaluation de
expr1/expr2expr1 retourne la liste
vide, l'évaluation de
expr1/expr2
Supposons, par exemple, que l'expression
expr1 retourne la liste (n1, n2,
n3) formée de trois nœuds. L'expression
expr2 est donc évaluée trois fois. Elle est
évaluée une première fois en prenant le nœud courant égal à
n1, la position du contexte égale à 1 et la taille du
contexte égale à 3. Elle est évaluée une deuxième fois en prenant le
nœud courant égal à n2, la position du contexte égale
à 2 et la taille du contexte égale à 3. Elle est évaluée une troisième
et dernière fois en prenant le nœud courant égal à
n3, la position du contexte égale à 3 et la taille du
contexte égale à 3. Si ces trois évaluations retournent respectivement
les listes (n0, n2, n5), (n1) et
(n0, n1, n2, n4, n6) et que l'ordre du document est
n0, n1, n2, n4, n5, n6, le résultat de l'évaluation
est la liste (n0, n1, n2, n4, n5, n6).
-
self::node()/child::*ou./* tous les élements qui sont enfants du nœud courant
-
child::*/child::*ou*/* tous les éléments qui sont des enfants des enfants du nœud courant
-
child::p/child::emoup/em tous les éléments
emenfants d'un élémentpenfant du nœud courant-
child::*/attribute::*ou*/@* tous les attributs des éléments qui sont enfants du nœud courant
-
parent::*/parent::*ou../.. le parent du parent du nœud courant
-
parent::*/child::*ou../* tous éléments qui sont frères du nœud courant, y compris le nœud courant
-
child::*/parent::*ou*/.. le nœud courant s'il contient au moins un élément ou aucun nœud sinon
-
descendant::p/child::emou.//p/em tous les élements
emqui sont enfants d'un élémentpdescendant du nœud courant-
descendant::*/descendant::*oudescendant::* tous les éléments descendants du nœud courant
ancestor::*/descendant::*tous les éléments du document
descendant::*/ancestor::*tous les ancêtres et tous les descendants du nœud courant ayant au moins un élément comme enfant si le nœud courant a au moins un élément comme enfant et aucun nœud sinon.
-
descendant::p/following-sibling::em[position()=1]ou.//p/following-sibling::em[1] premier frère
emd'un élémentpdescendant du nœud courant.-
child::*/position() liste
(1, 2, …, n)oùnest le nombre d'enfants du nœud courant.
L'opérateur '/' peut être cascadé et il est
associatif à gauche. Une expression de la forme
expr1/expr2/expr3(.
Ce parenthésage est très souvent inutile car l'opérateur
expr1/expr2)/expr3'/' est associatif à l'exception de quelques cas
pathologiques.
L'opérateur '/' peut aussi être employé dans
des expressions de la forme
/ qui sont l'analogue
des chemins absolus dans les systèmes de fichiers.expr2
Une expression de la forme
/ est évaluée de la
façon suivante. L'expression expr2expr2 est évaluée en
ayant, au préalable, fixé le nœud courant à la racine de l'arbre
contenant le nœud courant, la position dans le contexte à 1 et la taille
du contexte à 1. Une telle expression est donc équivalente à une
expression root(.)/.
La fonction expr2root() retourne la racine de l'arbre
contenant son paramètre.
Le nœud courant appartient très souvent à l'arbre d'un document
XML. Dans ce cas, la racine de cet arbre est un nœud de type
document node. Il est également possible que le
nœud courant appartienne à un fragment de document et que la racine de
cet arbre soit un nœud quelconque.
Les expressions de la forme
/ se comportent comme
des chemins absolus puisqu'elles s'évaluent en partant d'une racine.
Elles ne sont, toutefois, pas complètement absolues car la racine
choisie dépend du nœud courant. La racine choisie est celle de l'arbre
contenant le nœud courant.expr2
-
/ le nœud
document noderacine de l'arbre-
/child::*ou/* l'élément racine du document
-
/child::bookou/book l'élément racine du document si son nom est
booket aucun nœud sinon-
/child::book/child::chapterou/book/chapter les éléments
chapterenfant de l'élément racine du document si son nom estbooket aucun nœud sinon-
/descendant::sectionou//section tous les éléments
sectiondu document
Les opérateurs sur les ensembles réalisent les opérations d'union, d'intersection et de différences sur les ensembles de nœuds représentés par des listes classées dans l'ordre du document. L'opérateur d'union est très souvent utilisé alors que les deux autres opérateurs le sont plus rarement.
L'opérateur d'union est noté par le mot clé
union ou par le caractère '|'.
Les opérateurs d'intersection et de différence sont notés respectivement
par les mots clé intersect et
except.
-
child::* union attribute::*ou* | @* tous les attributs et tous les éléments enfants du nœud courant
-
*:* except xsl:* tous les éléments enfants du nœud courant qui ne sont pas dans l'espace de noms associé au préfixe
xsl-
@* except @id tous les attributs excepté l'attribut
id-
descendant::* intersect descendant::p/following::* tous les éléments descendants du nœud courant qui suivent un élément
pégalement descendant du nœud courant
Bien que les listes manipulées par XPath peuvent contenir des nœuds et des valeurs atomiques, ces opérateurs fonctionnent uniquement avec des listes représentant des ensembles de nœuds. Ils ne fonctionnent pas avec des listes contenant des valeurs atomiques. Les listes de nœuds retournées par ces opérateurs sont triées dans l'ordre du document et ne comportent pas de doublon.
Bien que XPath traite principalement des nœuds d'un document XML, il lui faut aussi manipuler des valeurs atomiques afin de sélectionner de façon précise les nœuds. Cette partie détaille les différents types pour les valeurs atomiques ainsi que les fonctions opérant sur ces valeurs.
Le type booléen xsd:boolean
contient les deux valeurs true et
false. Ces deux valeurs sont retournées
par les fonctions true() et
false() sans paramètre. Les parenthèses sont
obligatoires car l'expression XPath true donne les
éléments true enfants du nœud courant.
Les valeurs booléennes peuvent être manipulées à l'aide des
opérateurs and et or et de la
fonction not().
true() and false()falsetrue() or false()truenot(false())true
Les valeurs des autres types peuvent être converties explicitement
en des valeurs booléennes par la fonction xsd:boolean().
Elles sont aussi converties implicitement dès qu'une valeur booléenne
est requise. C'est le cas, par exemple, des filtres, de la structure de
contrôle if de XPath ou
des structures de contrôle xsl:if et xsl:when de XSLT.
Les règles qui s'appliquent alors sont les suivantes.
Une liste vide est convertie en
false.Une liste non vide dont le premier élément est un nœud est convertie en
true.Si la liste contient une seule valeur atomique, les règles suivantes s'appliquent. Rappelons qu'une valeur atomique est considérée comme une liste contenant cet objet et inversement.
Un nombre est converti en
truesauf s'il vaut0ouNaN.Une chaîne de caractères est convertie en
truesauf si elle est vide.
Les autres cas provoquent une erreur.
xsd:boolean(())donne
falsecar la liste est videxsd:boolean((/,0))donne
truecar le premier objet de la liste est un nœudxsd:boolean(0)donne
falsecar l'entier est égal à0xsd:boolean(7)donne
truecar l'entier est différent de0xsd:boolean('')donne
falsecar la chaîne de caractères est videxsd:boolean('string')donne
truecar la chaîne de caractères n'est pas vide
Les seuls nombres existant en XPath 1.0 étaient les nombres
flottants. XPath 2.0 manipule les nombres des trois types xsd:integer, xsd:decimal et xsd:double des schémas XML.
Fonctions sur les nombres
- Opérateurs
'+','-'et'*' Ces opérateurs calculent respectivement la somme, la différence et le produit de deux nombres entiers, décimaux ou flottants.
- ⊳
2+3, 2-3, 2*3 5, -1, 6
- ⊳
- Opérateur
div Cet opérateur calcule le quotient de la division de deux nombres entiers, décimaux ou flottants.
- ⊳
3 div 2, 4.5 div 6.7 1.5, 0.671641791044776119
- ⊳
- Opérateurs
idivetmod Ces opérateurs calculent respectivement le quotient et le reste de la division entière de deux entiers.
- ⊳
3 idiv 2, 3 mod 2 2, 1
- ⊳
number abs(number x)retourne la valeur absolue d'un nombre entier ou flottant. La valeur retournée est du même type que la valeur passée en paramètre.
- ⊳
abs(-1), abs(2.3) 1, 2.3
- ⊳
number floor(number x)retourne la valeur entière approchée par valeur inférieure d'un nombre décimal ou flottant.
- ⊳
floor(1), floor(2.5), floor(2,7), floor(-2.5) 1, 2, 2, -3
- ⊳
number ceiling(number x)retourne la valeur entière approchée par valeur supérieure d'un nombre décimal ou flottant.
- ⊳
ceiling(1), ceiling(2.5), ceiling(2.3), ceiling(-2.5) 1, 3, 3, -2
- ⊳
number round(number x)retourne la valeur entière approchée la plus proche d'un nombre décimal ou flottant. Si le paramètre est égal à n+1/2 pour un entier n, la valeur retournée est l'entier n+1.
- ⊳
round(1), round(2.4), round(2.5), round(-2.5) 1, 2, 3, -2
- ⊳
number round-half-to-even(number x, xsd:integer? precision)retourne le multiple de 10-precision le plus proche du nombre décimal ou flottant
x. La valeur par défaut deprecisionest0. Dans ce cas, la fonction retourne l'entier le plus proche dex. Sixest à égale distance de deux multiples, c'est-à-dire si sa valeur est de la forme (n+1/2)×10-precision, la fonction retourne le multiple pair.- ⊳
round-half-to-even(12.34,-1), round-half-to-even(12.34,1) 10, 12.3- ⊳
round-half-to-even(2.5), round-half-to-even(3.5) 2, 4
- ⊳
xsd:anyAtomicType min(xsd:anyAtomicType* list, xsd:string? col)retourne le minimum d'une liste de valeurs comparables pour l'ordre
lt. Le paramètre optionnelcolspécifie la collation à utiliser pour comparer des chaînes de caractères. Les valeurs sans type, c'est-à-dire de typexs:untypedAtomic, sont converties, au préalable, en flottants parxsd:double().- ⊳
min(1 to 6), min(('Hello', 'new', 'world')) 1, 'Hello'
- ⊳
xsd:anyAtomicType max(xsd:anyAtomicType* list, xsd:string? col)retourne le maximum d'une liste de valeurs comparables pour l'ordre
lt. Le paramètre optionnelcolspécifie la collation à utiliser pour comparer des chaînes de caractères. Les valeurs sans type, c'est-à-dire de typexs:untypedAtomic, sont converties, au préalable, en flottants parxsd:double().number sum(xsd:anyAtomicType* list)retourne la somme d'une liste de nombres. Les valeurs qui ne sont pas des nombres sont converties au préalable en flottants avec
xsd:double().- ⊳
sum(1 to 6) 21
- ⊳
number avg(xsd:anyAtomicType* list)retourne la moyenne d'une liste de nombres. Les valeurs qui ne sont pas des nombres sont converties, au préalable, en flottants avec
xsd:double().- ⊳
avg(1 to 6) 3.5
- ⊳
Les chaînes de caractères XPath contiennent, comme les documents XML, des caractères Unicode.
Une chaîne littérale est délimitée par une paire d'apostrophes
''' ou une paire de guillemets
'"'. Lorsqu'elle est délimitée par
une paire d'apostrophes, les guillemets sont autorisés à l'intérieur et
les apostrophes sont incluses en les doublant. Lorsqu'elle est, au
contraire, délimitée par une paire de guillemets, les apostrophes sont
autorisées à l'intérieur et les guillemets sont inclus en les
doublant.
- ⊳
'Une chaîne' donne
Une chaine- ⊳
'Une apostrophe '' et un guillemet "' donne
Une apostrophe ' et un guillemet "- ⊳
"Une apostrophe ' et un guillemet """ donne
Une apostrophe ' et un guillemet "
Les expressions XPath sont très souvent utilisées commme valeurs d'attributs d'un dialecte XML comme les schemas XML ou XSLT. Dans ce cas, les apostrophes ou les guillemets qui délimitent la valeur de l'attribut doivent être introduits avec les entités prédéfinies que cela soit comme délimiteur ou à l'intérieur d'une chaîne.
Il existe de nombreuses fonctions permettant de manipuler les
chaînes de caractères. Dans les exemples ci-dessous, les chaînes
apparaissant dans les valeurs des expressions sont écrites avec des
délimiteurs ''' bien que ceux-ci ne fassent pas
partie des chaînes.
Fonctions sur les chaînes de caractères
xsd:integer string-length(xsd:string s)retourne la longueur de la chaîne de caractères, c'est-à-dire le nombre de caractères qui la composent.
- ⊳
string-length('Hello world') 11
- ⊳
xsd:string concat(xsd:string s1, xsd:string s2, xsd:string s3, ...)retourne la concaténation des chaînes de caractères
s1,s2,s3, …. Le nombre de paramètres de cette fonction est variable.- ⊳
concat('Hello', 'new', 'world') 'Hellonewworld'
- ⊳
xsd:string string-join(xsd:string* list, xsd:string sep)retourne la concaténation des chaînes de caractères de la liste en insérant la chaîne
sepentre elles. Contrairement à la fonctionconcat, le nombre de paramètres de cette fonction est fixé à 2 mais le premier paramètre est une liste.- ⊳
string-join(('Hello', 'new', 'world'), ' ') 'Hello new world'
- ⊳
xsd:integer compare(xsd:string s1, xsd:string s2, xsd:anyURI? col)retourne la comparaison des deux chaînes de caractères
s1ets2en utilisant la collation optionnelle identifiée par l'URIcol. La valeur de retour est-1,0ou1suivant ques1est avants2pour l'ordre lexicographique, égale às2ou aprèss2. Sicolest absente, la collation par défaut est utilisée. Celle-ci est basée sur les codes Unicode.- ⊳
compare('Hello', 'world') -1- ⊳
compare('hello', 'World') 1
- ⊳
xsd:boolean starts-with(xsd:string s, xsd:string prefix)retourne
truesi la chaînescommence par la chaîneprefixetfalsesinon.xsd:boolean ends-with(xsd:string s, xsd:string suffix)retourne
truesi la chaînesse termine par la chaînesuffixetfalsesinon.xsd:boolean contains(xsd:string s, xsd:string factor)retourne
truesi la chaînefactorapparaît comme sous-chaîne dans la chaînesetfalsesinon.- ⊳
contains('Hello', 'lo') true
- ⊳
xsd:boolean matches(xsd:string s, xsd:string regexp, xsd:string? flags)retourne
truesi une partie de la chaînesest conforme à l'expression rationnelleregexpetfalsesinon. La chaîne optionnelleflagsprécise comment doit être effectuée l'opération.- ⊳
matches('Hello world', '\w+') true- ⊳
matches('Hello world', '^\w+$') false- ⊳
matches('Hello', '^\w+$') true
- ⊳
xsd:string substring(xsd:string s, xsd:double start xsd:double length)retourne la sous-chaîne commençant à la position
startet de longueurlengthou moins si la fin de la chaînesest atteinte. Les positions dans la chaînes1sont numérotées à partir de1. Les paramètresstartetlengthsont des flottants par compatibilité avec XPath 1.0. Ils sont convertis en entiers avecround().- ⊳
substring('Hello world', 3, 5) 'llo w'- ⊳
substring('Hello world', 7, 10) 'world'
- ⊳
xsd:string substring-before(xsd:string s1, xsd:string s2)retourne la sous-chaîne de
s1avant la première occurrence de la chaînes2danss1.- ⊳
substring-before('Hello world', 'o') 'Hell'- ⊳
substring-before('Hello world', 'ol') ''
- ⊳
xsd:string substring-after(xsd:string s1, xsd:string s2)retourne la sous-chaîne de
s1après la première occurrence de la chaînes2danss1.- ⊳
substring-after('Hello world', 'o') ' world'- ⊳
substring-after('Hello world', 'ol') ''
- ⊳
xsd:string translate(xsd:string s, xsd:string from, xsd:string to)retourne la chaîne obtenue en remplaçant dans la chaîne
schaque caractère de la chaînefrompar le caractère à la même position dans la chaîneto. Si la chaînefromest plus longue que la chaîneto, les caractères defromsans caractère correspondant danstosont supprimés de la chaînes.- ⊳
translate('Hello world', 'lo', 'ru') 'Herru wurrd'- ⊳
translate('01-44-27-45-19', '-', '') '0144274519'
- ⊳
xsd:string replace(xsd:string s, xsd:string regexp, xsd:string repl, xsd:string? flags)retourne la chaîne obtenue en remplaçant dans la chaîne
sles occurrences de l'expression rationnelleregexppar la chaînerepl. L'expressionregexppeut délimiter des blocs avec des paires de parenthèses'('et')'qui peuvent ensuite être utilisés dans la chaînereplavec la syntaxe$1,$2, ….- ⊳
replace('Hello world', 'o', 'u') 'Hellu wurld'où chaque caractère'o'a été remplacé par le caractère'u'- ⊳
replace('="\'\"=', '(["\\])', '\\$1') '=\"\\'\\\"='où un caractère'\'a été inséré devant chaque caractère'"'ou'\'- ⊳
replace('(code,1234)', '\(([^,]*),([^\)]*)\)', '($2,$1)') '(1234,code)'où les textes délimités par'(',','et')'ont été échangés
- ⊳
xsd:string* tokenize(xsd:string s, xsd:string regexp)retourne la liste des chaînes obtenues en découpant la chaîne
sà chaque occurence de l'expressionregexpqui ne peut pas contenir la chaîne vide.xsd:string normalize-space(xsd:string s)supprime les caractères d'espacement en début et en fin de chaîne et remplace chaque suite de caractères d'espacement consécutifs par un seul espace. Le résultat est du type
xsd:normalizedString.- ⊳
normalize-space(' Hello &x0A; world ') 'Hello world'où les deux espaces et le retour à la ligne au milieu ont été remplacés par un seul espace et où les espaces au début et à la fin ont été supprimés
- ⊳
xsd:string lower-case(xsd:string s)retourne la chaîne
smise en minuscule.- ⊳
lower-case('Hello world') 'hello world'
- ⊳
xsd:string upper-case(xsd:string s)retourne la chaîne
smise en majuscule.- ⊳
upper-case('Hello world') 'HELLO WORLD'
- ⊳
xsd:string codepoints-to-string(xsd:integer* list)convertit une liste de points de code en une chaîne de caractères.
xsd:integer* string-to-codepoints(xsd:string s)convertit une chaîne de caractères en une liste de points de code.
- ⊳
string-to-codepoints('A€0') (65, 8364, 48)
- ⊳
xsd:string normalize-unicode(xsd:string s, xsd:string? norm)retourne la normalisation de la chaîne
savec la normalisation spécifiée par la chaînenorm. Cette dernière peut prendre les valeursNFC,NFD,NFKCetNFKDà condition que chacune de ces normalisations soit implémentée. Sinormest absente, c'est la normalisation C (NFC) par défaut qui est utilisée. Celle-ci est toujours implémentée.- ⊳
normalize-unicode('ö') 'ö'où le caractère'¨'U+308est le caractère spécial tréma.
- ⊳
Quelques fonctions XPath comme matches(),
replace() et tokenize() prennent
en paramètre une expression rationnelle. La syntaxe de ces expressions
est identique à celle des expressions rationnelles des
schémas avec seulement quelques différences.
La principale différence avec les expressions rationnelles des
schémas est l'ajout des deux ancres '^' et
'$'. Ces deux caractères deviennent spéciaux. Ils
désignent la chaîne vide placée, respectivement, au début et à la fin de
la chaîne. Ces deux caractères sont utiles car la fonction
matches() retourne true dès qu'un
fragment de la chaîne est conforme à l'expression rationnelle. Pour
forcer la chaîne, prise dans son intégralité, à être conforme, il faut
ajouter les caractères '^' et '$'
au début et à la fin de l'expression rationnelle.
- ⊳
matches('Hello world', '\w+') donne
truecar les fragmentsHelloouworldsont conformes à l'expression\w+.- ⊳
matches('Hello world', '^\w+$') donne
falsecar la chaîne contient un espace.
Le fonctionnement des ancres '^' et
'$' est modifié par le modificateur
'm'.
Les fonctions matches() et
replace() prennent un dernier paramètre optionnel
flag qui modifie leur comportement. Ce paramètre
doit être une chaîne de caractères pouvant contenir les caractères
'i', 'm' et
's' dans n'importe quel ordre. Chacun de ces
caractères joue le rôle d'un modificateur qui
influence un des aspects du fonctionnement de ces fonctions.
Le caractère 'i' indique que la chaîne est
comparée à l'expression sans tenir compte de la casse des lettres.
Ceci signifie que les lettres minuscules et majuscules ne sont plus
distinguées.
- ⊳
matches('Hello world', 'hello') donne
false.- ⊳
matches('Hello world', 'hello', 'i') donne
true.
Le caractère 'm' modifie la signification des
ancres '^' et '$'. Il indique
que la chaîne est comparée à l'expression en mode
multi-ligne. Dans ce mode, la chaîne est vue
comme plusieurs chaînes obtenues en découpant à chaque saut de ligne
marqué par le caractère U+0A.
Ceci signifie que le caractère '^' désigne alors la
chaîne vide placée au début de la chaîne ou après un saut de ligne et
que le caractère '$' désigne alors la chaîne vide
placée à la fin de la chaîne ou avant un saut de ligne.
- ⊳
matches('Hello
world', '^Hello$') donne
false.- ⊳
matches('Hello
world', '^Hello$', 'm') donne
true.
Le caractère 's' modifie la signification du
caractère spécial '.'. Il désigne normalement tout
caractère autre qu'un saut de ligne. Avec le modificateur
's', il désigne tout caractère, y compris le saut de
ligne U+0A.
- ⊳
matches('Hello
world', '^.*$') donne
false.- ⊳
matches('Hello
world', '^.*$', 's') donne
true.
La liste est la structure de données fondamentale de XPath. Il
existe plusieurs opérateurs permettant de construire et de manipuler des
listes. La restriction importante des listes XPath est qu'elles ne
peuvent pas être imbriquées. Une liste XPath ne peut pas contenir
d'autres listes. Elle peut uniquement contenir des nœuds et des valeurs
atomiques. Ainsi, l'expression ((1,2),(3,4,5)) ne
donne pas une liste contenant deux listes de deux et trois entiers. Elle
donne la liste de cinq entiers que donne également l'expression
(1,2,3,4,5).
L'opérateur essentiel de construction de listes est ',' (virgule) qui permet de concaténer,
c'est-à-dire mettre bout à bout, des listes. Il est aussi bien utilisé
pour écrire des listes constantes comme (1,2,3,4,5)
que pour concaténer les résultats d'autres expressions. Contrairement
aux opérateurs de chemins,
l'opérateur ',' ne réordonne pas les éléments des
listes et ne supprime pas les doublons. Le résultat de l'expression
expr1,expr2expr1 suivies des valeurs du résultat de
l'expression expr2. Si une valeur apparaît
dans les deux résultats, elle a plusieurs occurrences dans le résultat
final. Par exemple, le résultat de l'expression
(1,2),(1,3) est bien la liste
(1,2,1,3) avec deux occurrences de l'entier
1.
Le fait qu'une valeur soit assimilée à la liste (de longueur 1)
contenant cette valeur simplifie l'écriture des expressions. Ainsi les
deux expressions (1),(2) et 1,2
sont équivalentes.
title, authordonne la liste des enfants de nom
titlepuis des enfants de nomauthordu nœud courant.1, 'Two', 3.14, true()donne la liste
(1, 'Two', 3.14, true)constituée d'un entier, d'une chaîne de caractères, d'un nombre flottant et d'une valeur booléenne.(1, 2), 3, (4, (5))donne la liste
(1, 2, 3, 4, 5)sans imbrication.(1, 2), 2, 1, 2donne la liste
(1, 2, 2, 1, 2)avec répétitions.
L'opérateur to permet de créer une liste
contenant une suite d'entiers consécutifs. L'expression
n1 to
n2n1,n1+1,n1+2,…,n2-1,n2 des entiers de
n1 à n2
compris. Cet opérateur est surtout utile avec l'opérateur for pour
itérer sur une liste d'entiers.
1 to 5donne la liste
(1, 2, 3, 4, 5)1, 2 to 4, 5donne la liste
(1, 2, 3, 4, 5)
Un filtre permet d'extraire d'une liste les objets qui satisfont
une condition pour former une nouvelle liste. Un filtre se présente
comme une expression entre des crochets '[' et
']' placée après la liste à filtrer.
Une expression de la forme
expr1[expr2]expr1 est d'abord évaluée pour donner une
liste l d'objets. Pour chaque objet
o de la liste l,
l'expression expr2 est évaluée en modifiant,
au préalable, le focus de la manière
suivante. L'objet courant est fixé à l'objet
o, la position du contexte est fixée à la
position de l'objet o dans la liste
l et la taille du contexte est fixée à la
taille de l. Le résultat de cette évaluation
est ensuite converti en une valeur booléenne en utilisant les règles de conversion. Le résultat
final de l'évaluation de
expr1[expr2]l pour lesquels
expr2 s'est évaluée en la valeur
true. Les objets sélectionnés restent bien sûr dans
l'ordre de la liste l. La liste résultat est
en fait construite en supprimant de la liste
l les objets pour lesquels
expr2 s'évalue en
false.
Lors de l'évaluation de l'expression suivante, l'objet courant qui
est retourné par '.' prend les valeurs
successives 1, 2,
3, 4 et 5.
Seules les valeurs paires satisfont la condition et sont
conservées.
Les filtres sont beaucoup utilisés dans les expression de chemin pour sélectionner des nœuds.
Plusieurs conditions peuvent être combinées à l'aide des
opérateurs booléens and et or. Les filtres peuvent aussi être enchaînés en
les mettant l'un après l'autre.
-
text[position() > 1 and position() < 4] donne les enfants
textdu nœud courant aux positions 2 et 3-
text[position() > 1][position() < 4] donne les enfants
textdu nœud courant aux positions 2, 3 et 4
Le second exemple montre que les filtres peuvent être enchaînés.
Il ne donne pas le même résultat que le premier exemple car les
positions retournées par la fonction position() du
second filtre sont celles dans la liste obtenue après le premier filtre.
Comme le premier enfant text a été supprimé, il y a
un décalage d'une unité.
Les expressions de chemins retournent des listes de nœuds triés
dans l'ordre du document et sans doublon. Au contraire, l'opérateur
',' ne supprime pas les doublons.
p[@align or @type]donne la liste des enfants
pdu nœud courant ayant un attributalignoutype.p[@align], p[@type]donne la liste des enfants
pdu nœud courant ayant un attributalignsuivis des enfantspayant un attributtype. Si un nœudppossède les deux attributs, il apparaît deux fois dans la liste.
Il existe des fonctions XPath permettant de manipuler les listes.
xsd:integer count(item()* l)retourne la longueur de la liste
l, c'est-à-dire le nombre de nœuds ou valeurs atomiques qui la composent.- ⊳
count('Hello world', 1, 2, 3) 4
- ⊳
xsd:boolean empty(item()* l)retourne
truesi la listelest vide etfalsesinon.- ⊳
empty(1 to 5) false
- ⊳
xsd:boolean exists(item()* l)retourne
truesi la listelest non vide etfalsesinon.- ⊳
exists(1 to 5) true
- ⊳
item()* distinct-values(item()* l)retourne une liste des valeurs distinctes de la liste
len supprimant les valeurs égales pour l'opérateureq.- ⊳
distinct-values((1, 'Hello', 0, 1, 'World')) (1, 'Hello', 0, 'World')
- ⊳
xsd:integer* index-of(item()* l, item() value)retourne la liste des positions de la valeur
valuedans la listel.- ⊳
index-of((1, 'Hello', 0, 1, 'World'), 1) (1, 4)
- ⊳
item()* subsequence(item()* l, xsd:double start xsd:double length)retourne la sous-liste commençant à la position
startet de longueurlengthou éventuellement moins si la fin de la listelest atteinte.- ⊳
subsequence((1, 'Hello', 0, 1, 'World'), 2, 3) ('Hello', 0, 1)
- ⊳
item()* remove(item()* l, xsd:integer pos)retourne la liste obtenue en supprimant de la liste
lla valeur à la positionpos.- ⊳
remove(1 to 5, 3) (1, 2, 4, 5)
- ⊳
item()* insert-before(item()* l1, xsd:integer pos, item()* l2)retourne la liste obtenue en insérant la liste
l2dans la listel1à la positionpos.- ⊳
insert-before(1 to 5, 3, 1 to 3) (1, 2, 1, 2, 3, 3, 4, 5)
- ⊳
item()* reverse(item()* l)retourne la liste obtenue en inversant l'ordre
- ⊳
reverse(1 to 5) (5, 4, 3, 2, 1)
- ⊳
Les comparaisons sont un aspect important mais délicat de
XPath. Elles jouent un rôle important en XPath car elles permettent
d'affiner la sélection des nœuds en prenant en compte leurs contenus. Il
est, par exemple, possible de sélectionner des éléments d'un document
dont la valeur d'un attribut satisfait une condition comme dans les
expressions item[@type='free'] et
list[@length < 5]. Les comparaisons sont délicates
à utiliser car leur sémantique n'est pas toujours intuitive.
Il existe deux types d'opérateurs pour effectuer des comparaisons entre valeurs. Les premiers opérateurs dits généraux datent de la première version de XPath. Ils permettent de comparer deux valeurs quelconques, y compris des listes, avec des résultats parfois inattendus. Les seconds opérateurs ont été introduits avec la version 2.0 de XPath. Ils autorisent uniquement les comparaisons entres les valeurs atomiques de même type. Ils sont plus restrictifs mais leur comportement est beaucoup plus prévisible. Ils nécessitent, en revanche, que les valeurs comparées soient du bon type. Ceci impose de valider le document avec un schéma ou de faire des conversions explicites de types avec les fonctions appropriées.
Il existe aussi l'opérateur is et les deux
opérateurs << et >>
permettant de tester l'égalité et l'ordre des nœuds dans le
document.
Les opérateurs de comparaison pour les valeurs atomiques sont les
opérateurs eq, ne,
lt, le, gt et
ge. Ils permettent respectivement de tester
l'égalité, la non-égalité, l'ordre strict et l'ordre large (avec
égalité) entre deux valeurs de même type. L'ordre pour les entiers et
les flottants est l'ordre naturel alors que l'ordre pour les chaînes de
caractères est l'ordre lexicographique du dictionnaire. Cet ordre
lexicographique prend en compte les collations.
2 ne 3donne
true2 lt 3donne
true'chaine' ne 'string'donne
true'chaine' lt 'string'donne
true
Ces opérateurs de comparaison exigent que leurs deux paramètres
soient du même type. Les constantes présentes dans le programme sont
automatiquement du bon type. En revanche, les contenus des éléments et
les valeurs des attibuts doivent être convertis explicitement à l'aide
des fonctions de conversion lorsque le document est traité
indépendamment d'un schéma. Pour tester si la valeur d'un attribut
pos vaut la valeur 1, il est
nécessaire d'écrire xsd:integer(@pos) eq 1 où
la valeur de l'attribut pos est convertie en entier
par la fonction xsd:integer. Les opérateurs généraux
de comparaison évitent ces conversions fastidieuses car ils effectuent
eux-mêmes des conversions implicites.
La contrainte d'égalité des types des valeurs n'est pas stricte.
Il est possible de comparer une valeur d'un type avec une valeur d'un
type obtenu par restriction. Il est également
possible de comparer des valeurs des différents types numériques
xsd:integer, xsd:decimal,
xsd:float et xsd:double.
Les opérateurs généraux de comparaison sont les opérateurs
'=', '!=',
'<', '<=',
'>' et '>='. Ils permettent
respectivement de tester l'égalité, la non-égalité, l'ordre strict et
l'ordre large de deux valeurs de types quelconques.
Les objets à comparer sont d'abord atomisés, ce qui signifie que les nœuds présents dans les listes sont remplacés par leur valeur pour obtenir uniquement des valeurs atomiques. Ensuite, la comparaison est effectuée de façons différentes suivant que les objets sont des listes composées d'une seule valeur (considérées alors comme une simple valeur) ou de plusieurs valeurs.
La façon de réaliser une comparaison entre deux valeurs atomiques dépend du type de ces deux valeurs. Suivant les types de celles-ci, certaines conversions sont effectuées au préalable puis elles sont comparées avec l'opérateur de comparaison atomique correspondant donné par la table suivante.
| Opérateur général | Opérateur atomique |
|---|---|
= | eq |
!= | ne |
< | lt |
<= | le |
> | gt |
>= | ge |
Lorsque les deux valeurs sont de type
xsd:untypedAtomic, celle-ci sont comparées comme des
chaînes de caractères. Lorsqu'une seule des deux valeurs est de type
xsd:untypedAtomic, celle-ci est convertie dans le
type de l'autre valeur avant de les comparer. Quand le type de l'autre
valeur est un type numérique, la valeur de type
xsd:untypedAtomic est convertie en une valeur de
type xsd:double plutôt que dans le type de l'autre
valeur. Ceci évite qu'une valeur décimale comme 1.2
soit convertie en entier avant d'être comparée à la valeur
1. Si les deux valeurs sont de types incompatibles,
la comparaison échoue et provoque une erreur.
Pour illustrer ces comparaisons, on considère le petit document suivant.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<list>
<item type="1">1</item>
<item type="01">2</item>
<item type="03">3</item>
<item type="1.2">4</item>
<!-- Erreur car 'str' ne peut être convertie en nombre flottant -->
<item type="str">5</item>
</list>
Les expressions suivantes sont évaluées sur le document précédent
en supposant, à chaque fois, que le nœud courant est l'élément racine
list du document. Pour chacune des expressions, le
résultat est une liste d'enfants item de l'élément
list. Il est décrit en donnant les positions de ces
éléments item sélectionnés. Le résultat
item[1], item[2] de la première expression signifie,
par exemple, qu'elle sélectionne le premier et le deuxième enfants
item.
item[@type=1]donne
item[1], item[2]car la valeur de l'attributtypeest convertie en nombre flottant avant d'être comparée à1. La valeur'01'est donc convertie en'1'.item[@type='1']donne
item[1]car la valeur de l'attributtypeest convertie en chaîne de caractères avant d'être comparée à'1'.item[@type=.]donne
item[1]car la valeur de l'attributtypeet le contenu de l'élémentitemsont convertis en chaînes de caractères avant d'être comparés.item[@type=1.2]donne
item[4]car la valeur de l'attributtypeest convertie en nombre flottant avant d'être comparée à1.2.item[xsd:double(.)=xsd:double(@type)]donne
item[1], item[3]car la valeur de l'attributtypeet le contenu de l'élémentitemsont convertis en nombres flottants avant d'être comparés.
Il faut faire attention au fait que les comparaisons peuvent échouer et provoquer des erreurs lorsque les types ne sont pas compatibles. Ce problème renforce l'intérêt de la validation des documents avant de les traiter.
Les comparaisons entre listes ont une sémantique très
particulière qui est parfois pratique mais souvent contraire à
l'intuition. Ce cas s'applique dès qu'un des deux objets comparés est
une liste puisqu'une valeur est identifiée à une liste de longueur 1.
La comparaison entre deux listes l1 et
l2 pour un des opérateurs =,
!=, <,
<=, > et
>= est effectuée de la façon suivante. Chaque
valeur de la liste l1 est comparée avec chaque valeur
de la liste l2 pour le même opérateur, comme décrit
à la section précédente. Le résultat global est égal à
true dès qu'au moins une des comparaisons donne la
valeur true. Il est égal à false
sinon. Cette stratégie implique en particulier que le résultat est
false dès qu'une des deux listes est vide quel que
soit l'opérateur de comparaison.
() = ()donne
falsecar une des deux listes est vide.() != ()donne
falsecar une des deux listes est vide.
L'exemple précédent montre que l'opérateur !=
n'est pas la négation de l'opérateur =, ce qui n'est
pas très intuitif.
() != (1)donne
falsecar une des deux listes est vide.(1) = (1)donne
truecar la valeur1de la listel1est égale à la valeur1de la listel2.(1) != (1)donne
falsecar l'unique valeur1de la listel1n'est pas différente de l'unique valeur1de la listel2.(1) = (1, 2)donne
truecar la valeur1de la listel1est égale à la valeur1de la listel2.(1) != (1, 2)donne
truecar la valeur1de la listel1est n'est pas égale à la valeur2de la listel2.
Dès que la comparaison de deux valeurs des listes
l1 et l2 échoue, la comparaison
globale entre les listes l1 et l2
échoue également. L'ordre des comparaisons entre les valeurs des deux
listes est laissé libre par XPath et chaque logiciel peut les effectuer
dans l'ordre qui lui convient. Lorsqu'une de ces comparaisons donne la
valeur true et qu'une autre de ces comparaisons
échoue, le résultat de la comparaison des deux listes est imprévisible.
Il est égal à true si une comparaison donnant
true est effectuée avant toute comparaison qui
échoue mais la comparaison globale échoue dans le cas contraire.
La sémantique des comparaisons de listes permet d'écrire
simplement certains tests. Pour savoir si une valeur contenue, par
exemple, dans une variable $n est égale à une des
valeurs de la liste (2, 3, 5, 7), il suffit d'écrire
$n = (2, 3, 5, 7).
L'opérateur is compare deux nœuds et retourne
true s'il s'agit du même nœud. C'est donc plus un
test d'identité que d'égalité. Il s'apparente plus à l'opérateur
'==' de Java qu'à la méthode
equals du même langage.
Les deux opérateurs '<<' et
'>>' permettent de tester si un nœud se trouve
avant ou après un autre nœud dans l'ordre du document.
Pour illustrer ces trois opérateurs, on considère le document minimaliste suivant.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <list length="2"> <item type="1">1</item> <item type="1">2</item> </list>
Les expressions suivantes sont évaluées sur le document précédent en supposant, à chaque fois, que le nœud courant est la racine du document.
list is list/item/parent::*donne
truecar il s'agit du même nœud qui est l'élément racine du document.list/item[1]/@type is list/item[2]/@typedonne
falsecar il s'agit de deux nœuds différents bien que les deux attributs aient même nom et même valeur.list << list/item[1]donne
truecar le père est placé avant ses enfants dans l'ordre du document.list/@length << list/item[1]donne
truecar les attributs sont placés avant les éléments enfants.list/item[1] << list/item[2]donne
true.
Un exemple pertinent d'utilisation de l'opérateur
is est donné par la feuille de style avec indexation pour regrouper les éditeurs et
supprimer leurs doublons dans le document
bibliography.xml.
Des structures de contrôle sont apparues avec la version 2.0 de
XPath. L'objectif n'est pas d'écrire des programmes complets en XPath.
Il s'agit plutôt de remplacer par des expressions XPath simples des
constructions plus lourdes des langages hôtes. Il est, par exemple, plus
concis d'écrire le fragment XSLT suivant
avec un test dans l'expression XPath. Dans l'exemple suivant, l'élément
a contient une expression XPath en attribut dont
le résultat devient la valeur de son attribut id.
Cette expression retourne la valeur de l'attribut
xml:id de l'élément courant si cet attribut existe ou
génère un nouvel identifiant sinon.
<a id="{if (@xml:id) then @xml:id else generate-id()}"/>
Elle est équivalente au fragment XSLT suivant où le test est
réalisé par un élément xsl:choose.
<a>
<xsl:choose>
<xsl:when test="@xml:id">
<xsl:attribute name="id" select="@xml:id"/>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="id" select="generate-id()"/>
</xsl:otherwise>
</xsl:choose>
</a>
L'opérateur if permet d'effectuer un test. Sa
syntaxe est la suivante.
if (test) thenexpr1elseexpr2
La sémantique est celle de if dans tous les
langages de programmation. L'expression test
est évaluée et le résultat est converti en une valeur booléenne. Si cette valeur
booléenne est true, l'expression
expr1 est évaluée et le résultat est celui de
l'expression globale. Sinon, l'expression
expr2 est évaluée et le résultat est celui de
l'expression globale.
La partie else
est obligatoire et ne peut pas être omise. Lorsque cette seconde partie
est inutile, on met simplement expr2else ().
if (contains($url, ':')) then substring-before($url, ':') else ''l'évaluation de cette expression retourne le protocole d'une URL placé avant le caractère
':'si celle-ci en contient un.
L'opérateur if est parfois remplacé par un
filtre. L'expression
if (@xml:id) then @xml:id else generate-id() est en
effet équivalente à l'expression plus concise (@xml:id,
generate-id())[1].
L'opérateur for permet de parcourir des listes
pour construire une nouvelle liste. Il ne s'agit pas d'une structure de
contrôle pour des itérations quelconques comme le for
ou le while des langages C ou Java. Il s'apparente
plus à l'opérateur map des langages fonctionnels
comme ML qui permet d'appliquer une fonction à chacun des objets d'une
liste.
La syntaxe de l'opérateur for est la suivante
où var est une variable et
expr1 et expr2
sont deux expressions. La variable var peut
uniquement apparaître dans l'expression
expr2.
forvarinexpr1returnexpr2
L'évaluation d'une telle expression est réalisée de la façon
suivante. L'expression expr1 est d'abord
évaluée pour donner une liste de valeurs. Pour chacune de ces valeurs,
celle-ci est affectée à la variable var et
l'expression expr2 est évaluée. Le résultat
global est la liste obtenue en concaténant les listes obtenues pour
chacune des évaluations de l'expression
expr2.
Le résultat de l'expression expr2 est
une liste qui peut donc contribuer à plusieurs valeurs de la liste
finale. Si, au contraire, ce résultat est la liste vide, il n'y a
aucune contribution à la liste finale.
La variable var introduite par
l'opérateur for est une variable muette. Sa portée
est réduite à l'expression expr2 après le mot
clé return. Aucune valeur ne peut lui
être affectée directement.
for $i in 1 to 5 return $i * $il'évaluation de cette expression donne la liste
(1,4,9,16,25)des cinq premiers carrésfor $i in 1 to 3 return (2 * $i, 2 * $i + 1)l'évaluation de cette expression donne la liste
(2,3,4,5,6,7)qui est la concaténation des trois listes(2,3),(4,5)et(6,7)for $i in 1 to 5 return if ($i mod 2) then () else $i * $il'évaluation de cette expression donne la liste
(4,16)des carrés des deux nombres pairs 2 et 4 pour lesquels$i mod 2donne0
Il est possible d'imbriquer plusieurs opérateurs
for. Il y a d'ailleurs une syntaxe étendue qui
permet une écriture concise de ces itérations imbriquées. Cette syntaxe
prend la forme suivante.
forvar-1inexpr-1, …,var-Ninexpr-Nreturnexpr
Cette expression est, en fait, équivalente à l'expression suivante écrite avec la première syntaxe.
forvar-1inexpr-1return for … return forvar-Ninexpr-Nreturnexpr
for $i in 0 to 2, $j in 0 to 2 return $i * 3 + $jl'évaluation de cette expression donne la liste
(0,1,2,3,4,5,6,7,8)qui est la concaténation des trois listes(0,1,2),(3,4,5)et(6,7,8)
L'opérateur some permet de vérifier qu'au moins
un des objets d'une liste satisfait une condition. Sa syntaxe est la
suivante.
somevarinexpr1satisfiesexpr2
L'évaluation d'une telle expression est réalisée de la façon
suivante. L'expression expr1 est d'abord
évaluée pour donner une liste de valeurs. Pour chacune de ces valeurs,
celle-ci est affectée à la variable var et
l'expression expr2 est évaluée. Le résultat
de l'expression globale est true si au moins une des
évaluations de expr2 donne une valeur qui se
convertit en true. Il est
égal à false sinon.
some $i in 0 to 5 satisfies $i > 4l'évaluation de cette expression donne la valeur
truecar la condition$i > 4est satisfaite pour$i = 5
L'opérateur every permet de vérifier que tous
les objets d'une liste satisfont une condition. Sa syntaxe est la
suivante.
everyvarinexpr1satisfiesexpr2
L'évaluation d'une telle expression est réalisée de la façon
suivante. L'expression expr1 est d'abord
évaluée pour donner une liste de valeurs. Pour chacune de ces valeurs,
celle-ci est affectée à la variable var et
l'expression expr2 est évaluée. Le résultat
de l'expression globale est true si toutes les
évaluations de expr2 donnent une valeur qui
se convertit en true. Il est
égal à false sinon.
every $i in 0 to 5 satisfies $i > 4l'évaluation de cette expression donne la valeur
falsecar la condition$i > 4n'est pas satisfaite pour$i = 0ou$i = 1every $i in 0 to 5 satisfies some $j in 0 to 5 satisfies $i + $j eq 5l'évaluation de cette expression donne la valeur
true
Les constructions les plus fréquentes des expressions XPath peuvent être abrégées de façon à avoir des expressions plus concises. Les abréviations possibles sont les suivantes.
En XPath 1.0, la formule '.' était
une abréviation pour self::node() et elle désignait
toujours un nœud. En XPath 2.0, elle désigne l'objet courant qui peut
être une valeur atomique ou un nœud.
Il faut remarquer que '//' n'est pas une
abbréviation de descendant-or-self::. Les deux
expressions //section[1] et
descendant-or-self::section[1] donnent des résultats
différents. La première expression donne la liste des éléments
section qui sont le premier enfant
section de leur parent alors que la seconde donne le
premier élément section du document.
Les motifs XPath sont des expressions XPath simplifiées permettant de sélectionner de façon simple des nœuds dans un document. Ils sont beaucoup utilisés par XSLT, d'abord pour spécifier des nœuds auxquels s'applique une règle mais aussi pour la numérotation et l'indexation. Ils répondent à une exigence d'efficacité. Le cœur de XSLT est l'application de règles à des nœuds du document source. Il est important de déterminer rapidement quelles sont les règles susceptibles de s'appliquer à un nœud. Dans ce but, les motifs n'utilisent qu'un sous-ensemble très limité de XPath. De surcroît, les motifs sont évalués de façon particulière, sans utiliser le nœud courant.
Les seuls opérateurs utilisés dans les motifs sont les opérateurs
'|', '/'
et '//' et leur imbrication est très
restreinte. Un motif prend nécessairement la forme suivante
expr-1|expr-2| ... |expr-N
où les expressions expr-1, …,
expr-N ne contiennent que des opérateurs
'/' et '//'. En outre, les seuls
axes possibles dans les motifs sont les deux axes
child::, attribute::. L'axe
descendant-or-self:: est implicite dans l'utilisation
de l'opérateur '//' mais c'est la seule façon de
l'utiliser dans un motif. En revanche, les tests portant sur les types
de nœuds comme text() ou comment()
et les filtres sont autorisés dans les motifs.
L'évaluation d'un motif XPath est réalisée de façon différente
d'une expression XPath classique. Celle-ci ne nécessite pas de nœud
courant. Un motif est toujours évalué à partir de la racine du
document. De plus, un motif commence toujours implicitement par
l'opérateur '//'. Le motif section
est, en fait, évalué comme l'expression //section. Il
sélectionne tous les éléments section du document.
Des exemples de motifs avec les nœuds qu'ils sélectionnent sont donnés
ci-dessous.
/la racine du document
*tous les éléments
sectiontous les éléments
sectionchapter|sectiontous les éléments
chapteretsectionchapter/sectiontous les éléments
sectionenfants d'un élémentchapterchapter//sectiontous les éléments
sectiondescendants d'un élémentchaptersection[1]tous les éléments
sectionqui sont le premier enfant de leur parentsection[@lang]tous les éléments
sectionayant un attributlangsection[@lang='fr']tous les éléments
sectiondont l'attributlanga la valeurfr@*tous les attributs
section/@langtous les attributs
langdes élémentssectiontext()tous les nœuds textuels
Le logiciel xmllint possède un mode
interactif avec lequel il est possible de se déplacer dans un document
XML comme s'il s'agissait d'un système de fichiers. Les nœuds du
documents XML sont assimilés à des répertoires (dossiers) et fichiers.
Ce mode interactif s'apparente à un interpréteur de commandes
(shell) dont le répertoire de travail devient le
nœud courant. Les commandes permettent de se déplacer dans le document
en changeant le nœud courant et en évaluant des expressions XPath par
rapport à ce nœud courant. L'intérêt de ce mode interactif réside bien
sûr dans la possibilité d'expérimenter facilement les expressions
XPath.
Le mode interactif de xmllint est activé avec
l'option --shell. Les principales commandes
disponibles sont alors les suivantes.
helpaffiche un récapitulatif des commandes disponibles.
cdpathchange le nœud courant en le nœud retourné par l'expression XPath
path.pwdaffiche le nœud courant.
xpathpathaffiche le résultat de l'évalution de l'expression XPath
path.cat [node]affiche le contenu du nœud
node.dir [node]affiche les informations relatives au nœud
node.grepstringaffiche les occurrences de la chaîne
stringdans le contenu du nœud courant.
Une session d'expérimentation du mode interactif de
xmllint avec le fichier de bibliographie
bibliography.xml est présentée ci-dessous.
bash $ xmllint --shell bibliography.xml / > grep XML /bibliography/book[1]/title : t-- 27 XML langage et applications /bibliography/book[2]/title : t-- 14 XML by Example /bibliography/book[5]/title : t-- 46 Modélisation et manipulation ... /bibliography/book[6]/title : t-- 25 XML Schema et XML Infoset /bibliography/book[7]/title : ta- 3 XML / > xpath bibliography/book[@lang='en'] Object is a Node Set : Set contains 2 nodes: 1 ELEMENT book ATTRIBUTE key TEXT content=Marchal00 ATTRIBUTE lang TEXT content=en 2 ELEMENT book ATTRIBUTE key TEXT content=Zeldman03 ATTRIBUTE lang TEXT content=en / > cd bibliography/book[3] book > xpath @lang Object is a Node Set : Set contains 1 nodes: 1 ATTRIBUTE lang TEXT content=fr book > cd .. bibliography >
| Opérateur | Action | Syntaxe | Exemples |
|---|---|---|---|
,
| Concaténation de listes |
E1,E2
|
1,'Two',3.14,true()
|
for
| Itération |
for $i in E1 return E2
|
for $i in 1 to 5 return $i * $i
|
some
| Quantification existentielle |
some $i in E1 satisfies E2
|
|
every
| Quantification universelle |
every $i in E1 satisfies E2
|
|
if
| Test |
if (E1) then E2 else E3
|
if ($x > 0) then $x else 0
|
/
| Enchaînement |
E1/E2
|
|
[ ]
| Prédicat |
E1[E2]
|
chapter[count(section) > 1]
|
and or not
| Opérations logiques |
E1 or E2
|
|
to
| Intervalle |
E1 to E2
|
1 to 5
|
eq ne lt le gt ge
| Comparaisons de valeurs atomiques |
E1 eq E2
|
$x lt $y
|
= != < <= > >=
| Comparaisons générales |
E1 = E2
|
$x < $y
|
<< is >>
| Comparaisons de nœuds |
E1 is E2
|
|
+ * - div idiv
| Opérations arithmétiques |
E1 + E2
|
$price * $qty
|
| union intersection except
| Opérations sur les listes de nœuds |
E1 | E2
|
/|*
|
instance of
cast as
castable as
treat as
| Changements de type |
E1 instance of type
|
$x instance of xsd:string
|